专场为观众提供专属福利:3 月 19 日当天到 3 月 24 日,上线观看 China AI Day 演讲,即可获得 NVIDIA 深度学习培训中心(DLI)大语言模型课程 75 折优惠码,请看文末具体规则解释。
China AI Day 线上专场分为四大主题:LLM AI Infra、LLM 云上工具链、LLM 推理、性能分析和 LLM 应用,NVIDIA 将与国内领先的云和互联网企业深入探讨 LLM 性能的极致优化,覆盖架构、训练、推理、量化、AI 工作流 RAG 等多个维度,并为您详细呈现 LLM 在互联网核心应用、芯片设计等领域的案例,帮助您了解如何使用 NVIDIA 端到端的软硬件结合的技术栈来驱动新增长。
GTC 2024 大会 China AI Day
线上专场议程一览
注册并预约观看 China AI Day 线上演讲
https://www.nvidia.cn/gtc-global/session-catalog/?search=SE63216%20SE63219%20SE63231%20SE63221%20SE63222%20SE63220%20SE63223%20SE62274%20%20SE61664%20SE63217%20SE63218%20SE63229%20SE63215&tab.allsessions=1700692987788001F1cG&ncid=so-othe-574584
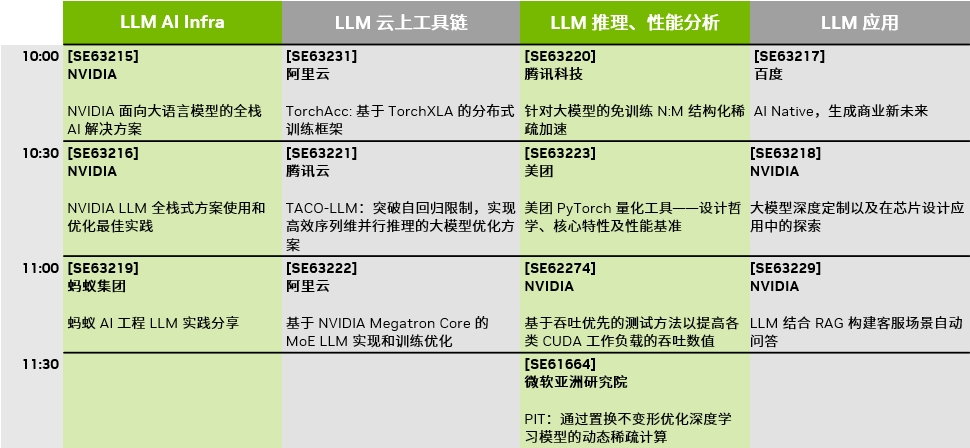
主题一:LLM AI Infra
10:00 - 10:25
NVIDIA 面向大语言模型的全栈 AI 解决方案
会议代码:SE63215
演讲人:王淼,NVIDIA 解决方案架构与工程总监

演讲简介:
深入探讨如何创建为大语言模型(LLM)设计的稳定、健壮且高效的数据中心架构。我们将利用 NVIDIA LLM 训练框架、Transformer Engine 上的 FP8 训练以及多精度训练 (MPT) 的能力,揭开 NVIDIA 针对 LLM 的全栈软件和硬件整体流水线的神秘面纱。此外,我们还将讨论 NVIDIA 训练和推理解决方案的最佳实践,包括 NVIDIA TensorRT™、TensorRT-LLM、Triton™ 推理服务器等,所有这些都是 NVIDIA AI Enterprise 套件的 AI 组件。这些内容将让您全面了解如何在 NVIDIA 加速的基础设施中优化 LLM 性能。
10:30 - 10:55
NVIDIA LLM 全栈式方案使用和优化最佳实践
会议代码:SE63216
演讲人:周国峰,NVIDIA 技术研发经理

演讲简介:
介绍基于 NVIDIA LLM 训练、推理和部署全栈式解决方案的使用和优化的最佳实践。重点介绍 Megatron-Core、TensorRT-LLM 和 Triton 推理服务器。Megatron-Core 是 NVIDIA 加速 LLM 大规模训练库,开发者可以基于它构建自己的 LLM 训练框架;TensorRT-LLM 是 NVIDIA 加速 LLM 推理的解决方案,开发者利用 TensorRT-LLM 可以在 GPU 上轻松取得 SOTA LLM 推理性能;Triton 推理服务器是 NVIDIA 部署推理服务的解决方案,它可以极大地简化基于 LLM 服务的部署,还包括了调度层的性能优化。
11:00 - 11:25
蚂蚁 AI 工程 LLM 实践分享
会议代码:SE63219
演讲人:张科,蚂蚁集团 AI Infra 部门负责人

演讲简介:
AI 工程一直是衔接基础硬件与算法创新的关键环节,其关键是解决上下游的效率问题,包括资源效率、系统效率、人的效率。蚂蚁 AI 工程团队一直致力于通过系统的智能化,解决整个系统的效率优化问题,全面覆盖了在离线训练推理引擎、在线服务、GPU 集群调度与虚拟化、工程智能等多个领域的效率提升。随着大模型时代的到来,对系统的效率又提出了更苛刻的要求,本次演讲将系统地介绍 AI 工程在大模型时代面临的挑战、基于 NVIDIA 技术栈的解法,以及工程效果等诸多方面。
主题二:LLM 云上工具链
10:00 - 10:25TorchAcc: 基于 TorchXLA 的分布式训练框架
会议代码:SE63231演讲人:林伟,阿里云研究员,阿里云人工智能平台 PAI 技术负责人

演讲简介:TorchAccelerator (简称 TorchAcc)是一个分布式训练加速框架,它能在 PyTorch 上将动态执行转化为基于图的中间表示。通过编译优化和手动算子优化,TorchAcc 可以有效加速 PyTorch 上的模型训练任务,并结合 NVIDIA CUTLASS 等计算库实现模型训练过程中 GPU 计算资源的高效利用。本次演讲将介绍围绕 TorchAcc 的工作内容,包括分布式策略、内存优化、运行时优化以及网络优化。
10:30 - 10:55
TACO-LLM:突破自回归限制,实现高效序列维并行推理的大模型优化方案
会议代码:SE63221
演讲人:叶帆,腾讯云异构计算专家工程师,异构研发负责人

演讲简介:
AI 发展面临算力绝对数量紧缺、受软件因素制约已有算力难以发挥到极致,以及 AI 中间层软件缺乏通用性及易用性制约应用快速接入算力等多方面困难。而腾讯云异构智算+TACO-LLM 为算力的有效供给提供了有力保障。
过去,行业里使用不同模型来实现不同任务。任务与算法高度绑定,只能进行任务与算法的协同设计,落到系统上,中间层要做很多不同的工作。现在,通过下游任务微调,同一个大语言模型可以实现不同任务。由于大模型高度统一了基础模型结构,我们得以专注于一个更狭窄的领域,应用、算法、系统之间可以进行协同优化,集中有限投入,应用的范围足够广阔。虽然不同公司的模型训练数据可能不同,但模型结构相似,足以使得好的中间层工具,可以最大程度发挥不同硬件的算力。
TACO-LLM 正是在这个背景下针对大模型重新设计的一整套优化加速及运行时的推理引擎。TACO-LLM serving 不仅支持普通格式的输出,也支持 OpenAI 格式的输出。用户可以使用诸如 LangChain 的组件快速将后端部署为 ChatOpenAI 的类型,无缝衔接到已有的应用流中,实现快速对接算力上线。
在优化设计上,社区的 vLLM 提出了基于 Paged Attention 的 continuous batching 的机制,极大地提升了推理效率,进一步释放了芯片算力,并优化了显存的编排与资源利用。但是大模型的自回归属性仍然极大影响了 MFU,距离充分释放 GPU 算力仍有极大空间。此外,当前几种不同的 Paged Attention 的实现在片上资源,例如 SRAM 的利用上,对越来越重要的长序列模型不够友好,仍很大程度上限制了算力的发挥。
TACO-LLM 从根本上打破了模型自回归的限制,在 Paged Attention 基础上实现了序列维并行推理,我们称之为 TurboSeq Paged Attention。我们重新设计了 Attention 计算的并行模式和流水编排,对片上资源的利用实现了常数复杂度,从而理论上可以支持任意长序列的高性能推理,极大提高了长序列模型的算力利用率。在运行时的调度和迭代编排上,我们也做了大量的优化,以保证计算的并发性,减少不必要的同步。
我们相信,依托腾讯云坚实可靠的 AI 基础设施硬件和自研 AI 基础软件,可以有效为市场提供多元、高效、优质的算力,为行业发展注入强劲动力。
11:00 - 11:25
基于 NVIDIA Megatron-Core 的 MoE LLM 实现和训练优化
会议代码:SE63222
演讲人:黄俊,阿里云资深算法专家

演讲简介:
以 ChatGPT 为代表的大语言模型(LLM)是当下实现通用人工智能最有潜力的技术路线。大模型在展现出惊人效果的同时,其高昂的训练和推理成本,一直是个巨大的挑战。模型稀疏化能有效降低训练和推理过程中的计算和存储消耗。近期以 Mixtral 为代表的 MoE(多专家混合)大模型,证明了稀疏 MoE 技术路线能够大幅降低训练和推理计算量,提升推理速度,同时模型效果能达到甚至超过同等规模的稠密模型。本次报告主要介绍阿里云人工智能平台 PAI (Platform of AI) 和 NVIDIA Megatron 在大规模 MoE 训练方面的合作研究工作,基于 Megatron Core 框架,实现了 MoE 训练工具,验证了工具的稳定性和收敛性,并在下游任务上验证了 MoE 大模型训练的效果。基于 PAI-Megatron-Patch 模型转换库,PAI 将上述 MoE 模型训练工具集成到阿里云灵骏大模型产品,极大地降低了用户在云端构建和优化 AI 模型的技术门槛。
主题三:LLM 推理、性能分析
10:00 - 10:25
针对大模型的免训练 N:M 结构化稀疏加速
会议代码:SE63220
演讲人:李运,腾讯科技高级算法研究员

演讲简介:
在本次会议中,我们将介绍一种基于 NVIDIA Ampere 和 Hopper 架构的结构化稀疏新算法,用于加速大模型推理。考虑到传统的稀疏预训练方案需要大量的数据、硬件资源和较长的训练周期,不利于其在大模型场景中的应用。因此,针对实际的业务场景需求,我们提出了一种无需训练的方法,该方法仅需要少量的校准样本便可实现大模型的稀疏化加速,同时不损失模型效果。此外,我们还将介绍一种新的 LLM 参数评估标准和参数筛选策略,以及这种独特的 2:4 结构化稀疏加速在腾讯搜索引擎中的应用。基于所设计的 LLM 稀疏化算法和高效部署方案,可以实现 1.25X 的推理耗时加速和 44% 的显存节省。
10:30 - 10:55
美团 PyTorch 量化工具 - 设计哲学、核心特性及性能基准
会议代码:SE63223
演讲人:李庆源,美团资深技术专家

演讲简介:
随着云计算负载的持续增长,降低神经网络模型部署成本的需求变得日益迫切。模型量化作为一项关键的压缩技术,可以使模型运行更快、体积更小,并且更具成本效益。为此,我们开发了一款即插即用的量化工具包——美团 PyTorch 量化工具(MTPQ),该工具包旨在利用 NVIDIA 的 TensorRT 以及 TensorRT-LLM 生态,实现模型在 GPU 上极致的推理性能。我们将介绍这个工具包的设计理念和主要功能,并分享其在工业界广泛使用的视觉模型以及大语言模型上的性能基准测试结果。
11:00 - 11:25
基于吞吐优先的测试方法以提高各类 CUDA 工作负载的吞吐数值
会议代码:SE62274
演讲人:董建兵,NVIDIA GPU 计算团队专家
赵新博,NVIDIA GPU 计算团队专家

演讲简介:
测试和比较不同硬件平台之间的性能是一项挑战性的任务,尤其是公平地比较 GPU 和 CPU 之间的性能。多数时候,都会选择以延迟为唯一的衡量标准来进行优化,但这种方式并不是对所有的场景都适用。因为某些应用场景追求的是在满足延迟限制要求的前提下,尽可能地提升应用的吞吐能力。尽管已经有许多测试吞吐的工具,例如 NVIDIA Triton 推理服务器,但如何高效地利用这些工具来分析和优化各类 GPU 工作负载仍然是一个难题。例如,如何确定并发程度、请求速率、在延迟约束的条件下提高吞吐、支持不同的 GPU 工作负载的并发方式(如多进程、单进程多流等)等软件、硬件组合。在本次演讲中,我们提出了一种吞吐优先的测试工具,来解决上述问题。其可以充分利用每个平台的所有硬件资源,并且能够在延迟约束的条件下追求更高的吞吐数值。结合 Nsight System 和 Nsight Compute 分析工具,使用我们的测试方法来对 CUDA 应用负载进行测试分析,可以显著提升各类 CUDA 应用在 GPU 上的吞吐表现。在演讲的后半部分,我们将介绍几个案例研究,以说明我们如何使用这种测试方法来优化信息检索、推荐系统和其他真实场景的性能。
11:30 - 11:55
PIT:通过置换不变形优化深度学习模型的动态稀疏计算
会议代码:SE61664
演讲人:韩震华,微软亚洲研究院高级研究员

演讲简介:
动态稀疏性,即在运行时才确定的稀疏模式,广泛存在于深度学习任务中,但是难于优化。现有的通过预处理特定稀疏模式的方法在应对动态稀疏计算时存在很大开销。我们提出了一种名为 PIT 的针对动态稀疏计算的深度学习编译器。PIT 提出了一种新颖的平铺机制,利用了置换不变变换(Permutation Invariant Transformation),在不改变计算结果的前提下,将多种稀疏模式的 Micro-tile 拼接成可以在 GPU 上高效运行的 Dense Tile,从而实现高 GPU 利用率和低覆盖浪费。通过我们提出的 SRead 和 SWrite 原语,PIT 可以以极快的检测计算的稀疏性来快速执行。对多种模型进行的广泛评估表明,PIT 可以加速动态稀疏计算高达 5.9 倍(平均 2.43 倍) 。
主题四:LLM 应用
10:00 - 10:25
AI Native,生成商业新未来
会议代码:SE63217
演讲人:刘林,百度商业研发部总监,商业 AIGC 平台负责人

演讲简介:
基于 LLM 技术的理解、生成、逻辑和记忆四大核心能力,百度营销全面重构商业生态,AI Native 全景应用落地,打造商业智能体,包括懂营销的 AIGC 创意内容生产平台“擎舵”、用自然语言即可创建营销方案的 AI Native 营销平台“轻舸”、全面提升广告投放效率与效果的商业动力引擎“扬楫”。全新商业智能体通过 LLM 技术驱动,基于自然语言的界面,使其能够理解客户的意图,帮助商家更好满足用户需求,同时利用生成式 AI 技术,实现从营销洞察到创意制作、广告投放到营销经营的全链路闭环,在底层的模型与架构层面,多项技术取得核心突破,打造业内领先水平。
10:30 - 10:55
大模型深度定制以及在芯片设计应用中的探索
会议代码:SE63218
演讲人:刘鸣杰,NVIDIA 研究科学家

演讲简介:
大模型深度定制在芯片设计应用中发挥重要作用。本演讲将介绍领域自适应技术,涵盖定制分词器、领域自适应连续预训练、具有领域特定指令的条件转移学习和领域适应的检索技术。通过在工程助手、聊天机器人、EDA 脚本生成和 Bug 总结分析等方面进行领域自适应,我们展示了最佳模型在芯片设计应用中明显优于通用基础模型的效果。
11:00 - 11:25
LLM 结合 RAG 构建客服场景自动问答
会议代码:SE63229
演讲人:齐家兴,NVIDIA 资深解决方案架构师

演讲简介:
互联网应用如电商、社交平台、短视频等通常拥有数量庞大的活跃用户。然而,随着用户数量的急剧增长,这些应用的客服系统也面临了一些挑战。用户在使用这些应用的过程中遇到问题时,会联系人工客服寻求帮助。但因用户基数庞大,客服系统所收到的用户问题展现出多样性和口语化等特点,这对传统的、基于文本匹配的自动回复系统带来很大的挑战。值得庆幸的是,大模型等相关技术的快速发展为解决这一难题带来了曙光。企业希望通过搭建基于大模型的自动客服问答系统,以更高效、准确的方式回答用户所遇到的问题,同时降低客服系统的人工成本。
本次演讲中,我们将介绍基于 LLM RAG 范式,将大模型与企业私有知识与数据相结合,使大模型能够根据用户问题,在客服场景下提供更准确且清晰的回复。大模型通过海量文本数据的训练和微调,能够提供流畅、连贯的对话体验。但是,由于训练过程没有涉及私有领域数据,所以直接将大模型应用在客服场景上的效果很难让人满意。为了解决这一难题,我们构建了基于 RAG 的 LLM 客服问答系统。该系统借助向量检索技术,将企业私有领域知识与 LLM 相结合,可为用户问题提供更准确且全面的回复。尽管 LLM 展现出强大的文本理解与生成能力,但其生成内容的不可控性以及容易出现幻觉等问题仍然存在。为此,我们针对客服场景的特点和要求,在普通 RAG 流程的基础上提出了多项算法优化方法,其中包括更精确地将无结构文本切割成语义明确的段落,从而提升召回准确率;借助 NVIDIA NeMo 框架,在私有领域数据上对大模型做了进一步的继续预训练和微调;添加重排序模型增加召回精度等。这些优化方法显著增强了大模型在客服场景中回答用户问题的准确率,在我们的测试中,客服问答系统准确率从 50% 提升至 81%,不仅降低了人工成本,也提升了用户满意度。
China AI Day 观众专属福利

“3 月 19 日至 3 月 24 日上线观看 China AI Day 任一演讲,赢取 NVIDIA 深度学习培训中心(DLI)大语言模型课程 75 折优惠码!”
期间上线参与 China AI Day 的观众,均将收到会后邮件,获得 NVIDIA DLI 公开课 75 折兑换码一张,可用于兑换下方任意一门课程。
NVIDIA DLI 大语言模型 (LLM)、生成式 AI 系列近期公开课:
4 月 11 日:深度学习基础——理论与实践入门
4 月 25 日:构建基于大语言模型 (LLM) 的应用
5 月 16 日:高效定制大语言模型 (LLM)
5 月 23 日:构建基于扩散模型的生成式 AI 应用
6 月 13 日:构建基于 Transformer 的自然语言处理应用
6 月 27 日:模型并行构建和部署大型神经网络
NVIDIA 诚邀您参加 China AI Day 线上专场,欢迎扫描上方二维码或点击阅读原文注册,并请持续关注 China AI Day 系列预告!与 NVIDIA 一起,深入洞察国内云和互联网企业领先的 AI 技术成果,了解大语言模型在不同领域的极致性能优化和应用吧!
如何登录和收藏 GTC China AI Day 演讲
步骤一:
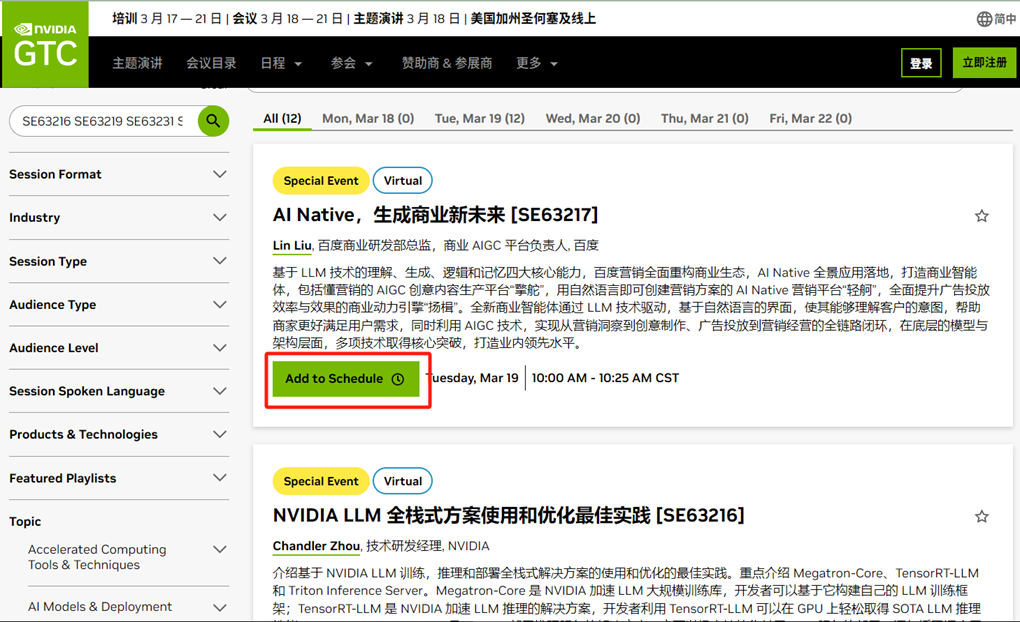
扫码打开链接,点击“Add to Schedule”绿色按钮登录
步骤二:
扫码打开链接,点击“Add to Schedule”绿色按钮登录
步骤三:
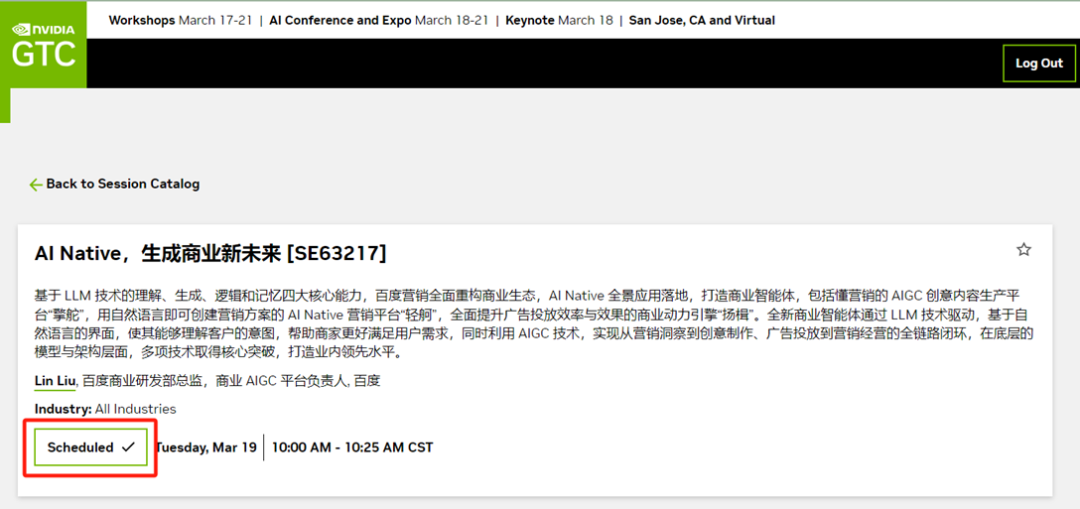
登录后,跳转到所选演讲的页面,
点击“Add to Schedule”绿色按钮预约该演讲
状态变为“Scheduled”即预约成功

 2024-03-14
2024-03-14

 8937
8937 0
0 0
0 0
0
