“万博士,快手什么时候开源可灵,让我们白嫖?”
作者|刘杨楠
编辑|赵健
AGI是什么?今天再看这个问题,依然满眼混沌,无从拆解。
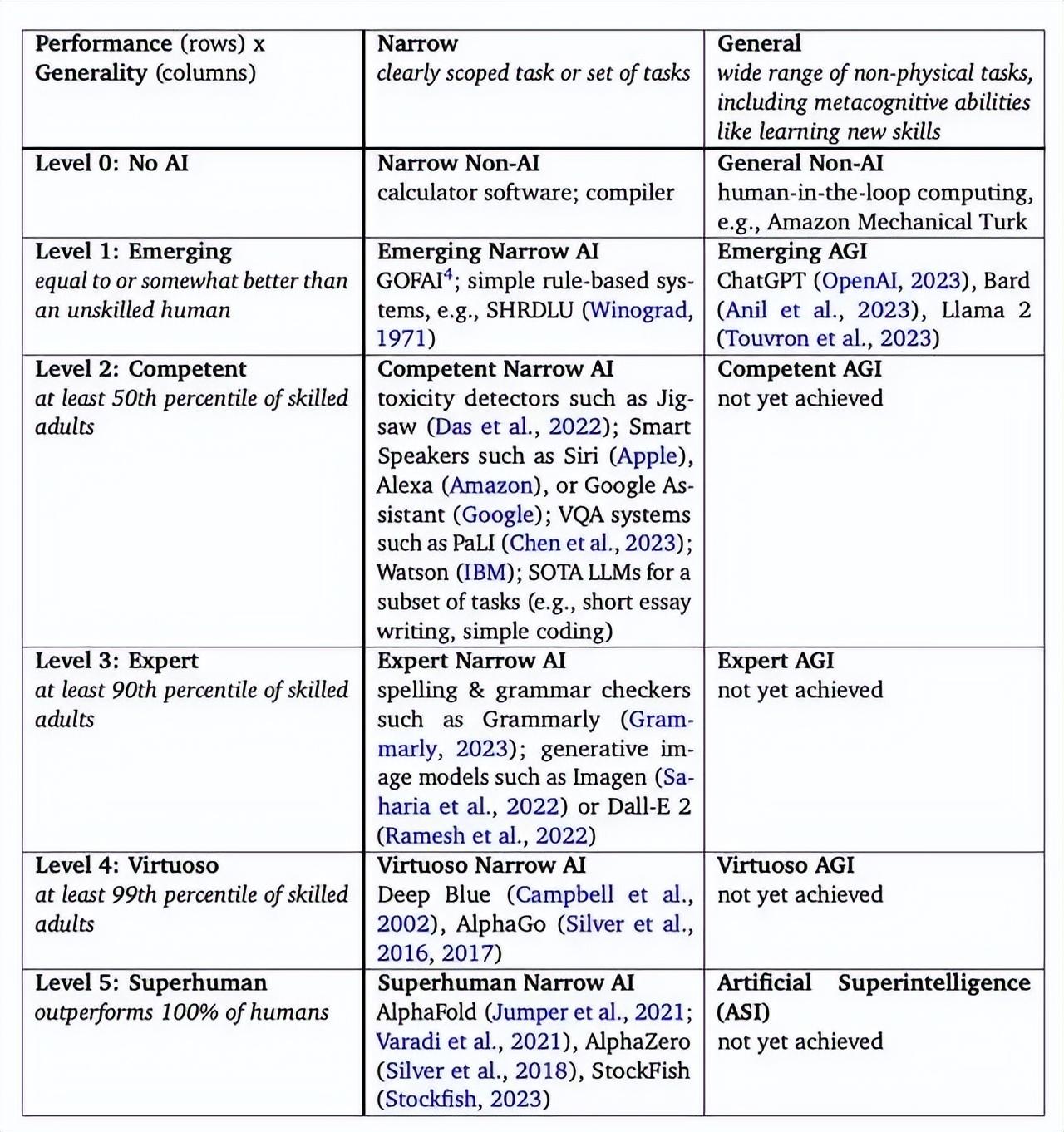
AGI一词,是由DeepMind联合创始人戴米斯·哈萨比斯在2010年提出的概念,他将AGI定义为“应该能够完成人类可以完成的几乎所有认知任务的系统”。去年,DeepMind发布论文,提出了AGI的五个分级:
OpenAI对AGI的定义是“在最具经济价值的工作中表现优于人类的高度自主系统”。OpenAI的使命是确保AGI造福全人类。
然而,近期一位谷歌软件工程师却表示,OpenAI“凭一己之力改变了游戏规则”,同时也使AGI的发展推迟了5-10年。
今时今刻,AGI近乎成为一种人类世界的新兴“宗教”,身处其中的人们各有各的信仰,也各有各的挣扎。有趣的是,尽管不同的人对AGI有不同的定义,但每个人都认为AGI是未来。
那么,“未来”又是什么?
在近期举办的2024智源大会上,智源学者、昆仑万维2050全球研究院院长颜水成,百川技术联合创始人谢剑,零一万物联合创始人黄文灏,快手视觉生成与互动中心负责人万鹏飞,与甲子光年创始人及CEO张一甲展开了一场观点交锋。
这是一场没有不限主题、不限时长的圆桌。一个多小时的时间里,五位嘉宾围绕端侧智能、多模态模型、AGI的定义以及前段时间沸沸扬扬的价格战展开讨论,并在论坛结束后和现场观众展开一番有趣互动。
纵然AGI的命题无比恢弘,今时今刻业内外关于AGI的想象又略显混沌,但在场观众的提问却极其“具体”:
“万博士,快手什么时候开源可灵,让我们白嫖?”
1. 未来,端上智能是非常重要的
张一甲:今天的配置非常有意思,有大厂,有创业公司,有产业派,听了今天所有的分享,大家有哪些新收获?
黄文灏:大部分的观点都已经形成行业共识,比如对Scaling Law和数据的认知。
谢剑:我基本也是赞同黄文灏的,我的感受是,去年国内的大模型技术生态没有那么大,今年很多技术做得都已经很好了。
颜水成:大家没有真正触及最最关键、最最隐秘、有价值的部分,都是讲自己有什么样的能力,但是我觉得从今年快手的可灵来看,能做到当前这个结果,绝对不仅仅是屏幕上展示的信息,应该有很多不便于分享的技术和创新,所以过去半年多的时间,还是在技术维度上有很多创新和进展。

智源学者、昆仑万维2050全球研究院院长颜水成
万鹏飞:我们做视频生成时面临挑战,相对来说不是很开放,整个事情做下来,创新点是有的,但是一些大的方向上我今天听下来,普遍认知是一致以及趋同的,大家对视频生成的关注度也比较高。大模型、AI被大家越来越关注,是很好的事情,各行各业能力和资源投进来,我相信我们是可以做得越来越好。
张一甲:苹果最近热度很高,对于前几天苹果在WWDC上发布的内容,哪些和你们心中的预期契合,哪些有不同意见?
万鹏飞:首先苹果做的事情和我之前做的很多事情有非常大的关系,我还是非常肯定这家公司的。比如他们在端侧模型上也做了很多,让移动端几亿用户用到AI能力,他推出的3B模型可以在iPhone 15运行。
很多应用场景确实不需要非常大的模型,包括现在的小模型通过更多的数据训练,展现出很好的性质,把成本问题解决;同时模型跑到用户手机上也有很好的隐私保护功能,综合能力非常强。
另外,苹果让我们意识到,生态位非常重要。从这个角度出发,我非常看好苹果在AI领域未来的应用。快手也有类似的生态,我们天然有很多应用场景,有一个很好的生态闭环和应用闭环。

快手视觉生成与互动中心负责人万鹏飞
张一甲:包括我退休的父母都在用AI产品,用起来AI就是很AI了,更多是从视觉、交互、触感。水成师兄怎么看苹果这次发布?
颜水成:最初我有很强的期待,因为最近出现一些模型和AI原生应用都非常智能的,你可以想象无穷无尽的场景。后来看到苹果在端侧的努力,恰好我当时在UIUC的室友去苹果做这一块的分享,让人觉得这个路径是对的。
有几个原因,原生多模态的大模型,受网络带宽和速度覆盖的影响,体验并不是特别好,必然有一部分东西上不到云端,最后一定需要有一个模式能在特殊的场景下,用端上的智能。未来端上智能是非常重要的,而且模型的体量和苹果手机所具备的相关的计算能力是绰绰有余去应付的,这可能会成为未来的趋势。小米、华为等也会同样重视端上智能。这一点值得期待。
谢剑:我分享两点,苹果一如既往地在产品定义和把握用户心智上非常成功,核心是希望做云端,核心贯穿的思想是智能只为你,一方面是“只为你”,另外一方面是“为你隐私考虑”。第二,技术上来说,如果是siri这么大的入口,更好的是变成和人一样的交互,但是这一次至少没有把原生的模型用上,一方面是苹果内部自己技术还没有做到,第二是如果和OpenAI合作可能更好。
张一甲:现场有一个很有趣的细节是,苹果每介绍完一个很牛的功能,就会紧接着强调一遍他们很安全。
颜水成:这是苹果的典型操作,就像其他手机厂商都出了折叠机,但苹果折叠机没有达到他们的要求,就一直没出一样,可能是苹果的原生大模型还没有达到他们的期待,还有更好的东西值得等待。
谢剑:如果苹果手里有技术,可能也是协同的技术,实时交互的数据太隐私了。
黄文灏:可以从三个层面讲,苹果的发布会给大家看到了很多应用的可能性,我们也提出了“模应一体”,模型和应用一块做,应用是很重要的一部分。
第二,从技术层面来看,我们有一个技术判断,我们先把模型做大,这个过程符合Scaling Law的法则。等模型能力够强之后,再想办法把模型做小,我们现在差不多可以做到参数规模缩小10-100倍,但模型能力基本不掉。
第三,从AGI的实现进度方面,会失望一点,包括苹果发布会、GPT-4o,我觉得这些技术都没有提高智能的上限。
2.多模态和语言,谁是实现AGI的主轴?
张一甲:今年整体上多模态的更新频率比较高,包括Pika、Luma AI、苹果和快手,基本都是原生多模态。而小川总之前经常表达,语言才是智慧的皇冠,才是实现AGI的唯一可取之路,其他都不是智慧的主轴,谢剑总你认同吗?
谢剑:首先把几个概念分一下,多模态不等于文生图、文生视频。多模态模型分成两部分,生成(text to any)和理解(any to text)。
第二,百川内部,我们对未来技术的大判断是,语言是智能的中轴心,但说“唯一路径”就太过于严格了。我们内部也在判断应该以什么样的方式投入多模态。
从技术上来看,Sora是text to video,文生视频过程中,语言模型没有发挥足够大的“中轴心”作用。未来我们希望实现any to any,现在any to text这个“理解”的过程已经通过scaling law等方法都可以做到,例如谷歌的Gemini;text to any这个“生成”的过程在diffusion架构上更加成功,这两个部分也许未来会汇合。
我们会持续聚焦提升智力的角度上,以语言为中轴心,any to text的多模态模型依然会做。当然也会有其他考虑,你看快手有这么多的视频data,也有text to video的应用前景依然非常广阔。

百川智能技术联合创始人 谢剑
张一甲:你所谓的“中轴心”,是从概念、产品视角,还是从智能目标的视角看?
谢剑:更多是从智能目标来看,语言更多是把人类的知识做抽象和压缩。从学习效率来看,把其他模态和语言做对齐,能够更好地提升智能学习效率是核心的点。
黄文灏:我发表一下我的看法,这里面有很大的探索空间,不一定是完全收敛的状态,可以说几个点:
一个是刚才提到的any to text,我的分享里面也提了,我们现在证明了一个事情,是说不同模态数据在同一个压缩空间做表示的,多模态数据可以提高智能的上限,这是一个很重要的事情。
第二,要实现any to any,大家要解决的问题是,生成和理解一起做,生成部分的loss对理解有没有帮助,有没有提升智能的上限。我们之前实验结果不是很惊喜,但最近对多模态数据做了很多处理,已经有一些实验结果,当然不是十分确定的结论,所以这是一个比较开放的问题,自己的实验条件下找到一个路。
最后,上午OpenAI的Sora负责人Aditya Ramesh(阿迪提亚·拉梅什)说过,LLM不一定是通向AGI的唯一路径,视频其实是可以通向AGI的路径,某种程度上我是同意的。现在我们优化的目标是给定算力条件下的智能水平,我同意谢剑的观点,语言效率更高,但是语言的数据会碰到瓶颈,或在scale up的时候学习效率是否能保持高水平的一致性?视觉数据可能比较少,效率低,但是可以利用更多算力,这是一个开放问题。只能说现在的算力条件和实验结果证明,语言是更加高效的表示方法,但不代表未来也一定是这样的,大家可以开放的探索,多模态没有一个最好的方法,有很多可以探索的东西。
张一甲:硅谷很多公司似乎对技术路线的选择没有太多执念,只要能达成他们的愿景,比如打造一款伟大的产品,采用什么技术路线其实无所谓。各位的核心目标是什么?
黄文灏:我们同意这个观点,但是每家公司愿景不一样,我们公司认为这个时代最大的机会以及公司的终极目标都是AGI,技术上更快达到AGI,就会有更多模型和应用的机会。

零一万物联合创始人 黄文灏
颜水成:专注语言维度,已经可以造就伟大的公司了。我们的公司目标是实现通用人工智能,让每个人更好的造就塑造表达自己。
万鹏飞:我们的目标是做“伟大的产品”。其实在这个时代,打造一个伟大的产品,最大的变量还是技术突破。如果做出一个非常好的产品,核心驱动力是技术突破,那这不就是殊途同归了?
谢剑:补充一下,百川也是超级模型+超级应用双轮驱动的,小川也表达过相似的观点,什么技术派和市场派都是盲人摸象。大家一谈AGI非常兴奋,但最终怎么做到那一步,一定是有和市场的结合,应用的结合,很多时候也需要用户的反馈,现在世界上唯一一家以AGI为目标的只有OpenAI了。
3.意识是AGI的关键吗?
颜水成:其中涉及一个很重要的问题,“如何定义AGI”,这个东西定义清楚了,这家公司到底是不是以AGI为目标就越来越清晰了。
谢剑:百川内部把ChatGPT的出现叫作“智能纪元”,ChatGPT的出现让我们看到了AGI的曙光。如果以自然语言处理为例,所谓的人工智能1.0时代,困扰大家的是,为什么所有任务都要用一个深度学习模型来做,能不能打造一个“all in one,one to all”的模型?ChatGPT语言模型让我们看到了曙光,打开了智能纪元的大门。
黄文灏:我比较惊讶,大家对于AGI没有很统一的定义,但在硅谷是有统一定义的,当AI能够替代人类白领80%-90%的工作,AGI就到了,这是一个完全量化的指标。按照这个标准,硅谷预计6年后会实现AGI,我们公司也按照这个标准来做规划。你可以理解6年做不到80-90%,OpenAI就失败了,OpenAI和Anthropic和投资人讲的都是这个问题。
谢剑:一定程度上我是赞同的,但是某些场景下,人类能很轻松解决的问题,万亿大模型才十几分的水平,所以还有很长的路要走。至于AGI到底什么时候实现,我很难预测,有人说是3年,有人说是6年。
颜水成:开始大家在讲AGI,定义都不一样,前面两位讲的评判标准是有道理的,AI能完成人类60-80%的事情就实现了AGI。同时,大部分人完成的事情AI都能完成,某种意义上AI也就具备了人的意识。
意识是什么呢?在心理学角度,在人的大脑里面,system 1到system 2有一个专门的空间,有点类似于总导演,会决定人的各种模态的信息,同时会提取记忆,比如说做逻辑推理等,大脑的各个区域合在一起,把信息广播到所有的系统里,产生视觉、听觉等,这就是Global workspace theory(全局工作空间理论)。
这个角度来说,要想实现AGI,首先必须要有意识。AGI一定是多模态的,相当于AGI最好的表现形式是超级智能体,它能够access到不同的单模态,可以去访问到各种不同的工具,可以去访问demo,去update memory,可以去更新各个单独的多模态模型。从这个角度来说,我们研究多模态还是非常有必要的。
另外, 因为我自己是做多模态出身的,人有70%的信息是通过视觉获得,而且视觉是一个3D信息,语音是一个1D信息,所以它的信息量就比其他的模态要多很多。因此从信息量来说,我们每天所消耗的信息,包括抖音和快手基本上都在消耗视觉数据。从这个角度来说,纯粹的文字要和视觉、音乐的东西结合。
万鹏飞:整体上我是赞同的。首先,ChatGPT是伟大的产品,iPhone是伟大的产品,但伟大的产品往往离不开牛逼的技术,技术和产品不能割裂来看。
第二,AGI一定是一个能移动的东西,一部分的智能应该是与世界交互中提取的。如果AI替代我们的工作,不单单是语言的能力,一定是多模态的,心理学家、社会学家做过实验,视觉信息量约占50%,语音和文本各占30%、20%,有非AI人士做的实验。在我看来,真正达到刚才AGI的模型一定是多模态的。
颜水成:还有一个有趣的结论,不同的模态,最终进行交互、推理的时候,他用的表述形式是语言,从某种程度上说明了语言的重要性,只有语言才可能实现自我反馈的,他是一个自我完善的模型,从里面生成的东西一定还在里面,图像是不行的,所以从这个角度说明了,现在为什么做多模态大模型,把其他模态插进去,还有一些相似性。
张一甲:你们如何判断AI是否拥有意识?
颜水成:客观来说,刚才讲的Global workspace和自我的关系不是特别强。子模块对子模块地把信息考虑进来了,这时候认为有了意识。但到底什么是意识,我们不是特别清楚,这是用一种偏数学的语言表述,但是self到底是什么东西,根本说不明白。
谢剑:其实我觉得现在我们讨论AGI,基本上都没有在谈意识。至少从判断标准来看,AI替代人类80%的工作,或者说智力上达到人类80%-90%和建立自我意识还是两个概念。比如让一个智能体拥有自我意识,他自己有自己的目标,有自己的使命,和让一个智能体能够接受你的command,完成任务,是两个不同的概念。我们的Levels of AGI的划分和让AI拥有意识两件事不是直接连接的,这是我的看法。
黄文灏:我有些个人观点,不代表我公司。前段时间,我思考了一些问题,假设一个模型听你说话时能自主决定我什么时候打断你,它可能就有意识了。人在对话时,有人会插话表示自己的观点,因为我是在思考你说的话,我一直在思考什么时候需要打断。
4.中美的AGI故事,注定有不同版本
张一甲:接下来快问快答一下。大家知道,在座没有字节和火山,阿里云和百度云的人,各位怎么看价格战?
颜水成:一开始我们就避开了这件事情,对于我们中型公司来说,新的产品非常重要。我们在做大模型时,先是有5个不同的APP事先定义好,有一个音乐APP、漫画APP、陪伴APP、游戏APP等。我们认为这些APP会是大模型落地的场景,所以我们模型的研发,至少有90%以上是对to C场景。
我们一直做出海的业务,中国一直卷,可能会出现类似于当年安防市场的情况,受价格战影响很大,我们觉得有可能在大模型也会发生类似的事情,本来是很好的生意,因为价格之争会变得没有那么好了。
万鹏飞:背后的本质问题不是价格,如果ROI是正的,价格低一点,成本更低,是可以的。快手的商业模式可以跑通,我们基于大模型产品,在整个生态的运转能以一个非常容易的方式创造价值,这个价值成本高一点、低一点不是那么关键。其他的公司本质上也是这个逻辑,客户满意的,公司跑通ROI,就是健康的范畴。
谢剑:回顾一下整个事件,其实云厂商没有降价,而是做了降本的技术优化,云厂商做的是“羊毛出在猪身上”的生意,我API给了你,哪怕这里不赚钱,可以在云的其他服务赚钱。对于百川而言,显然不是我们能做的商业模式。对创业公司来说,C端超级应用的突破是未来最大的商业模式,B端可能有其他附加价值的打法。
黄文灏:我提供两个视角,最早把价格降下来的是MoE,有些不一样的技术思路,都可以把成本降到1%。第二,大家仔细看一下每个公司的价格战,大家把价格降下来的都是最弱的模型,在低端模型做价格战意义不是特别大。
张一甲:商业逻辑大家看得比较清楚,大厂大闭环,小厂小闭环,大公司是用户买产品,产品买模型,模型买云计算,云计算买卡,然后顺手做二级市场。

甲子光年创始人及CEO 张一甲
5.“快手什么时候开源可灵,让我们白嫖?”
观众提问:万博士好,刚才聊到快手的使命,拥抱每一种生活。根据AGI的发展,每个人生成自己的视频,未来快手上是否会出很多理想美好的生活,而不是真实的生活呢?
万鹏飞:好问题,大模型回答的内容获取也依然要遵循内容社区的规范,用户的需求依然是以和现在相同的方式满足,并不一定会破坏短视频生态的结构,肯定会带来挑战,更会带来机会,我还是比较乐观的。
观众提问:既然如此,每个人都能生成视频,是否可以生成一个爽剧脚本,我去当女主呢?
万鹏飞:会考虑很多不同的方方面面,也许某种特定场景下,需要释放压力,给你带来一些快乐。视频创作者相对比较复杂,不太好预测,整体的发展很快,我们可以拭目以待。
观众提问:我也是快手的忠实粉丝,快手对普通用户推流更多一点,快手又比较接地气。刚刚的问题,什么时候全面开源,是大家比较关注的。
第二个问题,快手视频生成,算力等等都已经有定向内容,现在关心的是安全问题,如何保证前期数据的投入,生成,产品设计等等方面,保证生成的内容是在法律和道德允许的,请万总回答一下。
万鹏飞:首先关于开源白嫖,感谢你的坦诚,暂时不考虑,但是会逐步开放一些东西出去。第二个问题,社区治理肯定是重要的问题,这个问题需要一个阶段想办法解决,AI发展很快,带来新的挑战和问题。回答上一个提问,内容的社区,生态治理和规范,不管什么时代都是存在的,新的思路,新的想法,解决新的挑战。
观众提问:零一万物和百川都没有开放多模态,是因为资金不到位,还是技术问题,你们的规划是怎样的?
谢剑:您定义的多模态是文生图,文生视频吗?我们推出了百小应,不仅仅是文生图,文生视频,我们说上传一张图片,去交流,本质上也是多模态的输入,文本的输出,百小应现在就有这样的能力。
黄文灏:我们的多模态模型去年就开源了,刚才谢剑补充了,之前的观点是生成和理解统一来做,并不一定对智能的有帮助,所以没有走这条路径,今年会有增强的动态模型推出,我们觉得多模态的核心作用是提升智能的上界,而不是在应用上拓宽可玩性。

观众提问:我想问一下万博士,现在英伟达的GPU是全世界最领先的,快手也是第一阵营的,是不是在GPU方面发力,为我们国家争一口气呢?另外,快手和抖音在国内竞争比较激烈,想看一下快手是否逐渐超越抖音。
万鹏飞:第一个问题,我们还是有自知之明,非常期待我们国家能够突破各种算力的限制和瓶颈。第二个问题,快手超过抖音,我是有信心的,要是全国十几亿人都有信心,是不是就超过了,很多人没有使用过,不妨试一试。
张一甲:你能给现场的朋友做流量倾斜吗?
万鹏飞:我们是一个公平普惠、有规则的平台。
观众提问:各位老师好,问一下计算卡方面的问题,回望去年大模型技术不断爆发时,大模型厂商之间的竞争仿佛是卡数量的竞争,现在大模型后半场阶段,越来越多新的技术不断涌现,似乎发现用更少的资源达到更好的效果。卡的竞争不再是需要考虑的,我们发现技术生成的模型又出来了,卡肯定又是需要考虑的问题,我想问四位老师,未来还是会把囤卡放在首要考虑和现有的卡呢?
黄文灏:我没有说我们有多少卡。卡的数量是绝对算力,算法是相对算力,这两个肯定都是越大越好,作为创业公司来讲,和大厂很难比拼绝对算力,就要发挥创业公司的优势,人均卡比大厂多,其实就可以发挥卡的优势,研究提升相对算力的算法。模型做的好了,模型算力也会提升,随着商业化的模式,两者相辅相成的关系。我觉得在绝对量上很难短期之内有突破时,相对算力做突破,期待有一点可以做指数级突破。
观众提问:请教一下,去年各个做大模型的厂商和业务方向比较统一,今年近期很多公司往to C方向出了很多APP,这个方向怎么考虑和思考呢?
黄文灏:去年可能也不是很统一,提到了大家的技术发展路径都是不一样的,比如说我们做全球化的模型和应用,中国也是非常重要的市场。比如说在中国没有特别想做to B,因为还是有一些传统问题,中国和美国不一样。大家都有自己的主张,并没有说开始就做to B赛道,现在都是沿着当时的主张,继续往下做,差异化也做的越来越大,AGI路上大家都是同行者,逐渐做了一些分化。
颜水成:to B的速度会更快一些,大模型出来做POC可以很快的卖给第三方,to B到最后上线获客,周期比较长,可能是一种感觉,很多公司开始做的时候,想清楚自己到底是toC还是to B。
谢剑:百川成立时更大的目标是在C端,我自己的感觉和解读,去年没有那么多C端应用,去年模型水平本身也没有到很好的水平,前期如果3.5都做不到,这个时候的模型能力想要支撑很好的应用不现实。今年逐步接近4,在很多场景下,C端能够真正做到价值增益。
张一甲:今天的圆桌论坛就到这里,今天的论坛到此结束,谢谢大家!
(封面图及文中配图来源:2024北京智源大会)

 2024-06-25
2024-06-25

 7900
7900 0
0 0
0 0
0
