通往AGI的道路千万条,多模态大模型是极其重要的一条。
无论是Sora的发布引起的关于“世界模型”的讨论,还是Midjourney、Adobe Firefly、快手可灵、Runway Gen-3、Vidu等模型的爆火,抑或是作为具身智能机器人“大脑”出现,能感知多维环境信息、提升机器人适应性和创造力的VLM(Vision-Language-Model)……显然,多模态大模型的浪潮已不可阻挡。
据Gartner预测,建立在多模态大模型上的生成式AI应用,将从2023年的1%,激增至2027年的40%,未来的市场充满了想象空间。
然而,当今市面上绝大多数的多模态模型,要么采用Sora的Diffusion Transformer(DiT)架构,要么采用大语言模型+CLIP的训练方式。
尽管都能实现多模态的感知和生成,但是各个模态之间本质上是仍然是独立的,仍然需要各种显性或者隐性的pipeline进行连接。这种“各模态分开训练”的方式不仅模型复杂度高、训练数据需求量大,数据融合难度大,而且无法真正做到对图像和视频的理解,很容易造成信息的损耗和丢失。
时代呼唤能真正理解物理世界、实现端到端输入和输出的原生多模态大模型。
2024年10月21日,智源研究院正式发布原生多模态世界模型Emu3。该模型只基于下一个token预测,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成。
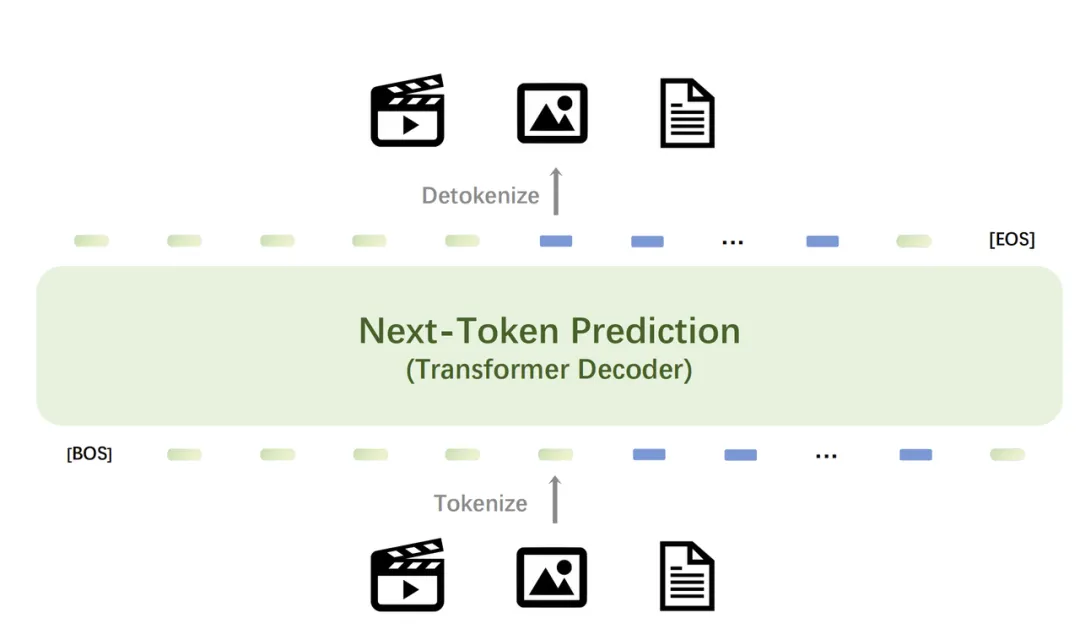
Emu3架构示例 图源:智源研究院
“World in One,One for World”。在媒体沟通会上,智源研究院院长王仲远用这样一句话形容Emu3的价值。
或许,中国原生多模态大模型时代正在到来。
1.真正的原生多模态大模型
“人工智能感知、理解物理世界的终极技术路线不是以语言大模型为核心对齐和映射其他模态的技术路线,而是应该采取统一模型的范式,实现多模态的输入和输出,让模型具备原生的多模态扩展能力,向世界模型演进。”
这是今年6月的智源大会上,王仲远对于大模型发展技术路线做出的预测。当时,他还预告了智源要发布多模态原生大模型的消息。
仅仅四个月之后,智源就兑现了他的承诺。
Emu3大模型通过下一个token预测的方式成功实现了视频、图像、文本三种模态的统一理解与生成,而且在图像生成、视觉语言理解、视频生成任务等表现上,也超过了SDXL 、LLaVA-1.6、OpenSora等知名开源模型。
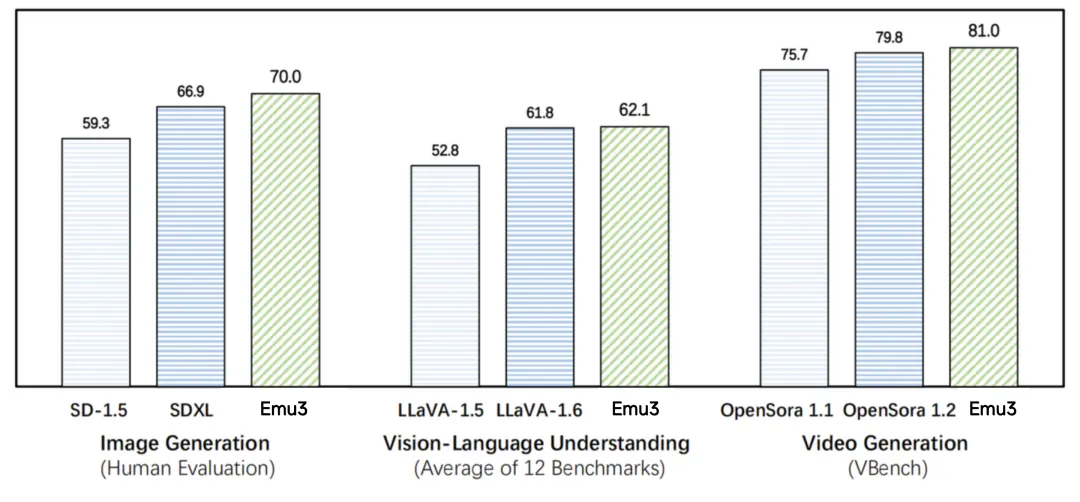
图注:在图像生成任务中,人类评估得分Emu3高于SD-1.5与SDXL。在视觉语言理解任务中,12 项基准测试的平均得分,Emu3领先于LlaVA-1.6与LlaVA-1.5。在视频生成任务中,VBench基准测试得分,Emu3优于OpenSora 1.2。图源:智源研究院
具体而言,Emu3用一个从零开始训练的Transformer模型处理所有类型的数据——它提供了一个强大的tokenizer,能够将视频和图像转换为token。这些视觉离散token可以与文本tokenizer输出的离散token一起送入模型中,并统一到一个离散的token空间的。接着,Emu3通过auto-regressive(自回归)的方式一个接一个地预测序列中的token,然后生成文本、图像和视频。
这种算法架构给模型带来了高度的灵活性,不仅为Any-to-Any的任务提供了更加统一的研究范式,也使得直接偏好优化(DPO,是一种优化方法,旨在直接优化模型预测的用户偏好,而不是传统的间接优化指标)能无缝应用于自回归视觉生成,使模型与人类偏好保持一致。
简单来说,使用Emu3,用户不仅可以生成对世界有着准确理解的图片,还可以预测后面的视频帧,生成更符合现实世界物理规律的视频。

Emu3文生图案例 图源:智源研究院

用户问题: Describe the landmark.
模型回答: The image showcases the Brooklyn Bridge, a prominent suspension bridge in New York City, recognized by its distinctive towers and the web of cables that support it. This iconic structure connects the boroughs of Brooklyn and Manhattan.
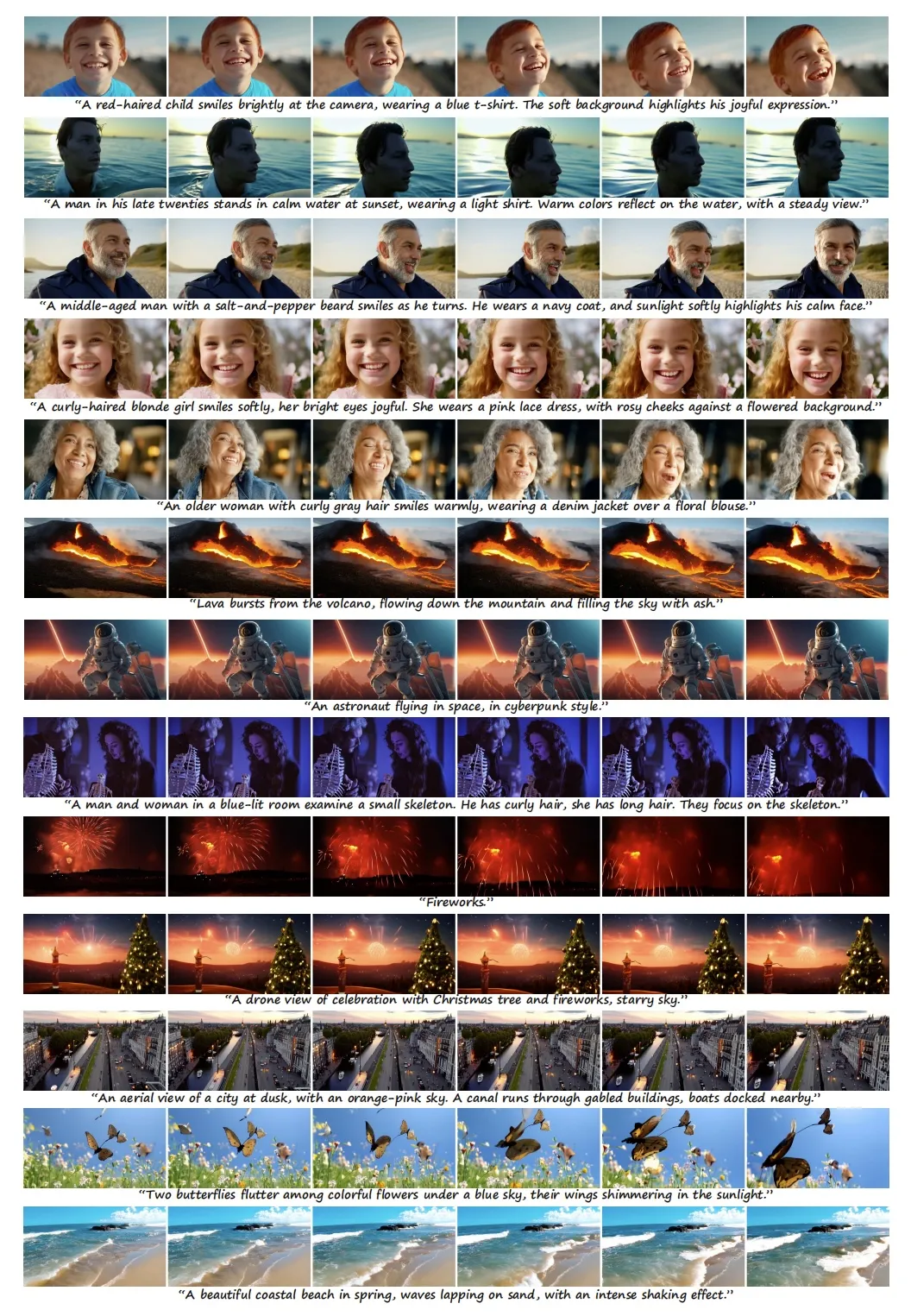
Emu3文生视频过程帧画面展示 图源:智源研究院
除了算法上的创新,优秀的生成效果和优质的训练数据也不无关系。
Emu3的训练数据很大一部分来自于之前悟道系列Aquila天鹰大语言模型的训练数据,以及训练前两代多模态大模型Emu1、Emu2时候积累的数据。同时,智源研究院还和北京电视台签署了战略合作协议,北京电视台的部分视频数据也将被持续用于Emu3的训练过程中。
“作为科研机构,过去我们在大语言模型上为行业带来了一些基础的思潮和创新指引。在多模态大模型上,我们觉得也需要为行业指明一条新的方向。”王仲远说。
2.“自回归是多模态大模型的下一代技术路线”
曾几何时,关于哪种技术路线能带来AGI的争论喋喋不休。
尽管GPT和Claude、Llama等一系列大语言模型的成功证明了基于“next-token-prediction”的自回归路线的有效性。但却也不乏Yann LeCun等学者出来唱衰,认为现在的大模型“比猫还笨”,并且提出了基于自监督路线的联合嵌入预测架构(JEPA)。
LeCun的质疑不无道理。
“next-token-prediction”被认为是通往AGI的可能路径,但这种范式在语言以外的多模态模型中没有被证明。多模态的生成任务很长一段时间里被扩散模型(例如 Stable Diffusion)主导,而多模态的理解任务则由组合式的方法(例如CLIP视觉编码器与LLM结合)所主导。而由于效率、并行化能力和长依赖处理等问题,自回归的技术路线鲜少在多模态大模型的训练中被采用。
在王仲远看来,LeCun观点的核心在于他认为大语言模型到不了AGI,而这在某种意义上也说明了探索多模态模型自回归路线的重要性。
“大语言模型为什么比猫还笨?因为仅凭文本是无法理解世界的。猫或其他动物天然地就在凭视觉感知世界,因此我们也有很多学者在研究通过视觉信号触发智能的能力。语言的确很重要,但如果要做到对世界有足够的理解,它首先要看到、感知到,才能把不同模态的信息交互,进而做到理解。”王仲远说。
王仲远认为,一个真正的AGI需要做到“理解”这个世界,多模态大模型也不例外。
相较于DiT和LLM+CLIP,自回归技术路线的优势在于,它做到了生成和理解的统一,只用一个Transformer模型就能处理所有类型的数据,不仅具备可扩展性,而且可以复用现在的算力基础设施进行训练,极大节省了算力资源。
“Emu3目前的视频生成质量已经可以比肩Open Sora这种开源的模型,未来随着参数量、数据质量、训练效率的提升,甚至能生成具有情节的长视频、具备更强的推理能力,实现比Sora更强的效果。”王仲远介绍。
智源研究院将此次Emu3的发布比作大语言模型领域里的GPT-3时刻。在 GPT-3 之前,所有人工智能技术都是专用系统,模型不通用;而作为一个单一模型,GPT-3展现出来的“暴力美学”让人们看到了通用语言智能的可能性,这是NLP几十年发展以来大家一直在追求、却始终无法实现的理想。
Emu3统一了文字、图像和视频理解与生成的技术路线对多模态大模型领域有着同样的意义。
王仲远表示,原来学术界和产业界都对auto-regressive(自回归)到底能不能做图像和视频的生成持怀疑态度,但智源研究院认为,大一统的原生多模态大模型是大模型发展道路上必须去攻克的技术方向。
尽管也有很多国际同行在做大模型基础技术路线的研究,但在多模态大模型领域,智源是首个训练出成熟模型并面向国际社会发布的。
“智源研究院作为一个科研机构,我们会做高校做不了、企业不愿做的事情。所以一方面我们会坚持原始创新,另一方面我们也希望为世界多模态大模型的训练范式指明一个方向。”王仲远说。
3.加速具身智能和科学计算的发展
无论是大语言模型还是多模态模型,最终的目标都是实现AGI。
在去年的智源人工智能大会上,智源研究院理事长黄铁军总结了三条实现AGI的技术路线:
大数据+自监督学习+大算力形成的信息类模型,以OpenAI的GPT系列模型为代表;
基于虚拟或真实世界,通过强化学习训练出来的具身模型,以Google DeepMind的DQN深度学习技术为代表;
直接抄自然进化的作业,复制数字版本的人脑和智能体,即脑智能。
可以看出,除了大语言模型之外,黄铁军也十分看好具身智能和科学计算的发展,而这也是智源研究院目前着重布局的两个方向。
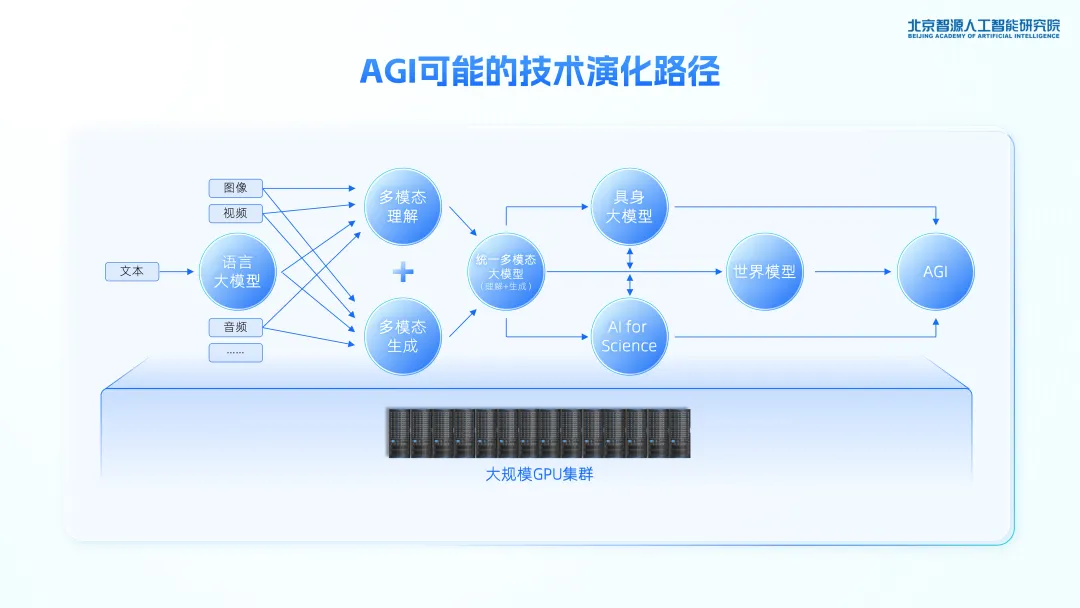
AGI可能的技术演化路径 图源:智源研究院
由于可以与物理世界交互、并在此过程中不断发展智能体的学习能力,具身智能被认为是通往AGI的关键道路之一。
据不完全统计,今年以来“具身智能”融资事件超50起,其中最高一笔融资近10亿元,其热度可见一斑。而多模态大模型,作为具身智能的“大脑”,是具身智能感知和理解世界、与物理世界实现交互的重要基础。
Emu3证明了下一个token预测能在多模态任务中有高性能的表现,这为构建多模态AGI提供了广阔的技术前景。换句话说,Emu3有机会将基础设施建设收敛到一条技术路线上,为大规模的多模态训练和推理提供基础,这一简单的架构设计将有利于产业化。
未来,多模态世界模型将促进机器人大脑、自动驾驶、多模态对话和推理等场景应用。
而将大模型应用于基础科学的AI for Science(科学计算),则是实现AGI的另一条重要道路。
今年的诺贝尔物理学和化学奖都颁发给了AI领域的科学家,这标志着AI与基础科学深入融合时代的到来。AI for Science将极大加速和扩展科学研究的效率和能力边界,底层科学的第一性原理也将成为AI向AGI进化的根本驱动和扩展引擎。
“大模型永远不可能只存在数字世界里,Emu3的技术路线是非常有潜力加速AI for Science的发展。”王仲远说,“就像蛋白质和DNA的研究,它是需要有图像的,这时候如果只靠大语言模型无法解决这些问题,还需要有视觉等多模态的理解和推理能力,这就是为什么我们认为Emu3‘大一统’的技术路线是更优的。”
尽管目前8B参数的Emu3模型已经可以很好地理解物理世界、生成更符合现实世界逻辑的图像和视频,但在智源看来,随着后续算力、数据和模型参数的扩大,以Emu3为代表的原生多模态大模型还将体现出更加令人惊叹的能力。
“Scaling Law在多模态大模型领域是存在的。 事实上我们内部也有试验过更小的模型,包括1.8B的模型,到了8B之后,我们发现模型的效果确实是在变好。所以我们可以预计,如果模型参数进一步提升,那么多模态大模型的语言能力、跨模态理解能力也会大幅提升。”
同时,算法上的进步,也将为Emu3这种原生多模态大模型的未来发展打开更多的可能性。
“我们现在还是一个dense(稠密)的架构,未来还可以尝试往MoE模型发展。原来在大语言模型上可能的发展趋势和路径,未来在多模态大模型上可能都能得到验证。”王仲远说。
(封面图来源:智源 Emu3 官网)

 2024-10-23
2024-10-23

 10826
10826 0
0 0
0 0
0
