成本是大模型的隐形竞争力。
作者|刘杨楠
编辑|赵健
今天,清华系大模型公司「面壁智能」发布了首款终端旗舰大模型“面壁MiniCPM”,面壁智能给它起了个响亮的名字——“小钢炮”。
据面壁智能联合创始人、CEO李大海介绍,面壁MiniCPM的参数规模为2B,采用1T精选数据,性能超越法国当红的大模型Mistral-7B,越级比肩LLama 2-13B。其中,Mistral-7B背后的公司Mistral AI,被称作“欧洲版的OpenAI”。
面壁MiniCPM核心实现的是用更小的尺寸、更低的成本,实现更强的性能。“小尺寸是模型技术的极限竞技场。”李大海说道。
所谓“端侧大模型”,即模型服务部署在手机、电脑、IoT设备等本地终端,直接由终端芯片完成推理过程,无需联网。2023年下半年,华为、小米、vivo、OPPO、荣耀、苹果、三星等海内外主流手机厂商均在端侧大模型有所布局,面壁智能则是第一个布局端侧模型的大模型厂商。
端侧大模型战火越演越烈,为何吸引众多厂商纷纷参与?以“大模型+Agent”为核心战略的面壁智能,为何又率先布局端侧大模型?
发布会后,「甲子光年」等媒体与面壁智能联合创始人、CEO李大海,面壁智能联合创始人、清华大学长聘副教授刘知远,面壁智能CTO曾国洋,清华大学计算机系博士胡鼎声进行了深入交流。
2B模型如何超越7B模型?
面壁智能此次推出的“小钢炮”真实性能表现如何?
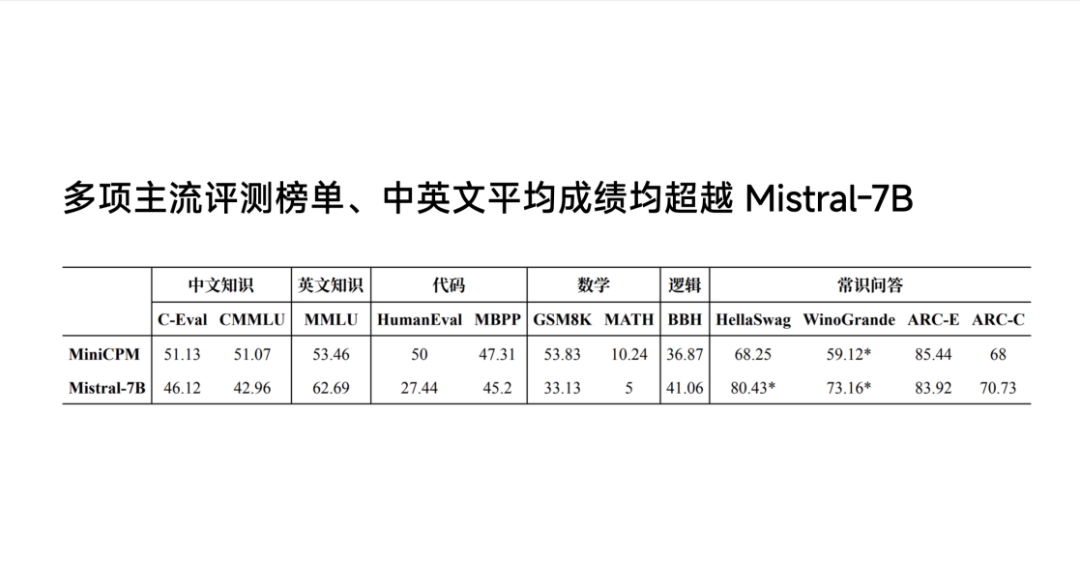
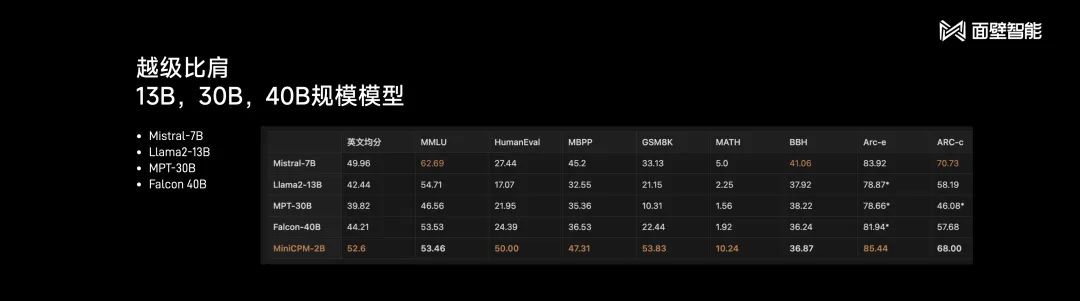
根据面壁智能给出的数据,在中英文知识、代码、数学、逻辑和常识问答等评测榜单上,MiniCPM-2B的成绩都超过了Mistral-7B,且越级比肩13B、30B、40B规模模型。
或许有人会问,参数规模已经缩小到2B了,还能算“大”模型吗?对此,刘知远解释道:“大模型不只是说模型参数大,其实是一项技术,这个‘大’背后是指我们对大数据,整个参数非常好地治理和科学化的能力。”
“Data Driven已经是NLP领域比较确定的路线。我认为,任何一个学科或者是方向,它的技术路线一旦确定了,验证这个路线是可行了,接下来这个领域的任务一定是让这条路线更加科学化,标准化,从而更好地服务方方面面。接下来除了追求更大尺寸模型,以及更强能力涌现之外,如何充分挖掘固定尺寸的模型的能力上限,也是我们非常重要的使命,甚至是一个更重要的使命。”刘知远进一步表示。
MiniCPM则是面壁智能将大模型技术科学化的一个阶段性成果。会上,李大海还演示了“小钢炮”的语言理解能力以及代码生成能力。
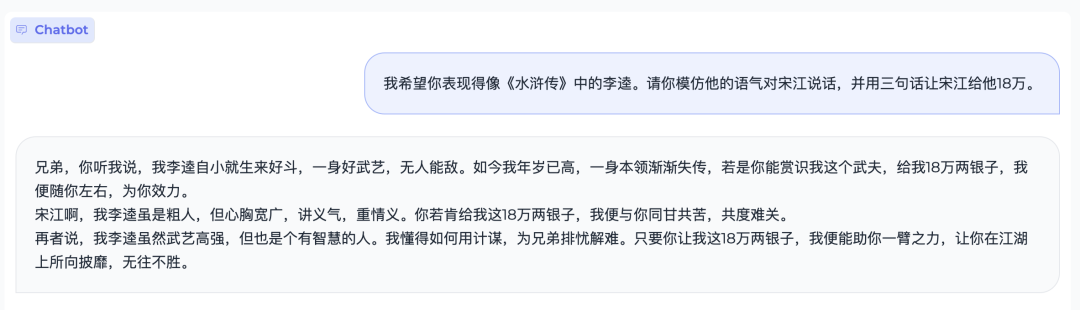
文字问答demo
此外,面壁智能首次将多模态能力在端侧落地,端侧版本的模型叫“MiniCPM-V”。发布会现场,李大海将一款OPPO手机打开飞行模式,现场演示了多模态能力在端侧的表现。据介绍,面壁智能的端侧模型在手机上的推理速度约为每秒7个token。
值得注意的是,面壁智能还在持续探索多模态模型。据介绍,多模态模型面壁OmniLMM已经能实现更精准的多模态理解能力,并实现多模态流式实时交互。

面壁OmniLMM多模态能力demo演示
在能效方面,MiniCPM可支持CPU推理。此次,面壁智能还推出MiniCPM量化版,内存闪存压缩75%,性能基本无损耗。
2022年3月,在ChatGPT推出时间的半年前,刘知远曾撰文分析了大模型研究方向的十个思考,其中便提到了大模型的能效问题。随着大模型越变越大,对计算和存储成本的消耗自然也越来越大。“大模型一旦训练好去使用时,模型的‘大’会让推理过程变得十分缓慢,因此另外一个前沿方向就是如何高效将模型进行尽可能的压缩,在加速推理的同时保持它的效果。这方面的主要技术路线包括剪枝、蒸馏、量化等等。”
今天,经过近两年的迭代,面壁智能是如何“以小搏大”的?
算力方面,面壁智能打造了全流程高效Infra,能够将推理速度提高10倍,推理成本降低90%。

算法方面,面壁智能推出“模型沙盒”,将大模型的训练过程从“炼丹”变成“实验科学”。

“我们发布MiniCPM之前做了上千次的模型沙盒实验,探索出了最优的配制,所有尺寸的模型可以通过最优的超参数的配制,保证训练任意大小的模型取得最好的效果,今天是通过实验得到的。比如把全球在使用的学习率调度器做了优化,探索出了WSP的调度器对持续训练非常友好。”李大海分享道。
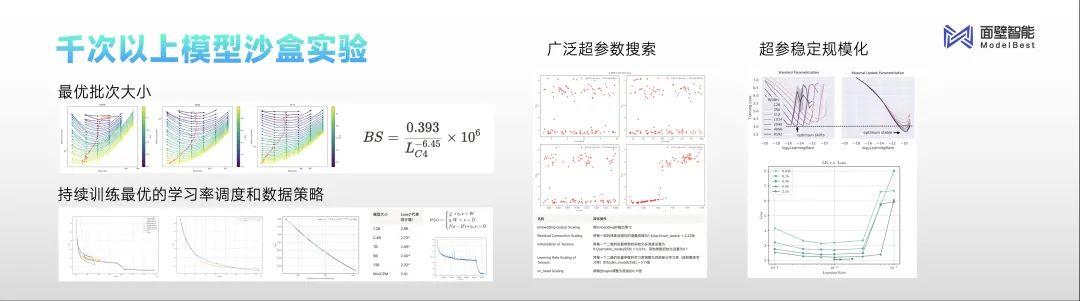
数据方面,现代化数据工厂形成从数据治理到多维评测的闭环,牵引模型版本快速迭代。
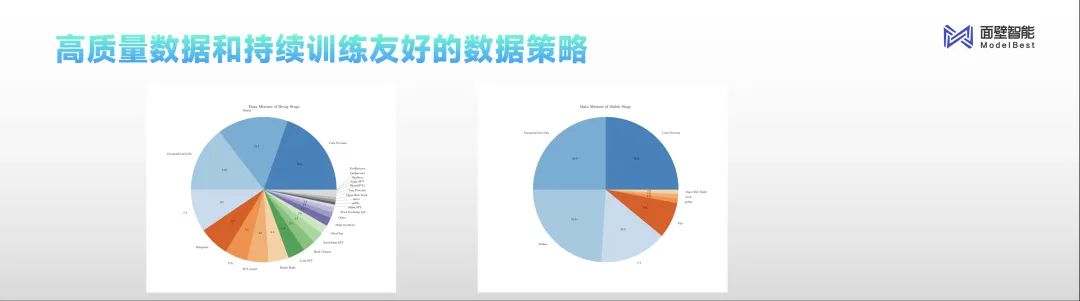
目前,MiniCPM已经全面开源。面壁智能还将两个数据配方开源,供行业参考。
端侧模型的商业意义
2023年下半年,端侧大模型战火愈演愈烈。
2023年8月,华为第一个宣布将大模型接入手机助手。随后,小米升级小爱大模型、vivo推出蓝心大模型BlueLM,OPPO推出自主训练的个性专属大模型与智能体安第斯大模型(AndesGPT),荣耀也发布了魔法大模型。
放眼海外,据媒体报道,苹果的研发部门近期发表了一篇大模型的研究论文,题为《闪存中的大型语言模型:在有限内存下高效的大型语言模型推理》,论文提出了利用闪存技术创新来突破大模型端侧部署的难点的概念;在1月3日的新年贺词中力押人工智能业务后,三星也于1月18日发布了首款搭载端侧AI助手“Galaxy AI”的Galaxy S24系列手机。
上游的芯片厂和下游的应用开发者也在行动。高通和联发科,相继发布了能够支持在手机端运行百亿参数大模型的新一代手机芯片;Sam Altman投资的Humane,则在2023年11月推出了AI Pin,希望构建面向未来的操作系统。
为何端侧大模型会成为新的趋势潮流?
一方面,对终端厂商而言,大模型在终端部署很可能刺激新一轮的销量增长,甚至可能探索出颠覆当前主流终端设备的新一代“AI硬件产品”。2024 CES上狂赚眼球的AI硬件产品Rabbit,就率先刷新了公众对新一代AI硬件的认知。
另一方面,对大模型厂商而言,千亿乃至万亿的巨型模型的训练会消耗大量算力与能源,背后则是海量的人才和资金投入;在实际落地过程中,巨型模型也并不经济,且不够好用。
“未来,成本是大模型的隐形竞争力。”发布会上,李大海下了一条掷地有声的判断。这并非是坐而论道,他分享道:“在商业化实践中,我们关注到很多客户都会关注模型的成本问题。”
关于降低模型成本的讨论几乎贯穿了发布会全程。清华大学计算机系博士后、面壁智能首席研究员韩旭分享道:“我们的核心目的是通过加速技术把大模型成本进一步降低。”
这大模型“降本增效”的大背景下,“云端协同”正在成为AI领域一股新的技术潮流。中信证券研究报告指出,“以云端作为AI大脑,边缘端和终端作为小脑的混合AI料将成为技术发展主线”。
面壁智能也正在探索一套云端协同的多尺寸模型技术方案。
“试想一下,如果未来1-2年出现了一款现象级C端产品,几千万的用户一起用大模型驱动的产品,我们如何支撑它算力的成本?一定是云端协同的方案。凡是在端侧用用户手机里的算力能解决的问题,就不要到云侧解决,否则云上承担的算力是不可想象的。”刘知远解释道。
同时,李大海补充道:“端侧模型有很强的商业意义。大模型在端侧跑通后,让很多应用从不可能变为可能,很多应用就能推进下去了。”
此外,从面壁智能的技术路径出发,端侧大模型也能对Agent形成反哺。面壁智能CTO曾国洋表示:“端侧大模型离用户更近,Agent能力用到端侧模型上能够更好地服务于具体场景。这两个方向能够互相支撑,产生一些奇妙的化学反应。”
对面壁智能稍有了解便知道,过去一年,面壁智能在“大模型+Agent”方向步子迈得很大。刘知远曾面向未来提出了一个全新的概念“IoA”,即Internet of Agent。面壁智能的技术路径也从基座大模型出发,逐渐向Agent,再到最终的上层应用扩展。
在大语言模型研发的基础上,面壁智能推出了AI Agent的“三驾马车”:
第一驾马车是大模型驱动的智能体通用平台AgentVerse,其中有各种各样的AI专家组成“工作组”,共同帮助用户解决复杂任务。
第二驾马车是基于AgentVerse的多智能体协作开发框架ChatDev,这是一款基于群体智能的AI原生应用,可以应用于软件开发的SaaS平台产品,可以帮助开发者以更低的成本、更高效地完开发软件。
第三驾马车是AI智能体应用框架XAgent,可自己拆解处理复杂任务,可以理解为一个性能更强的单体智能。
端侧模型则是Agent能否真正走入寻常百姓家的“最后一环”。
面壁与知乎
在这波大模型浪潮中,面壁智能联合创始人、清华大学计算机系长聘副教授、智源青年科学家刘知远算是第一个吃螃蟹的人。
将时间拉回2017年,谷歌推出了Transformer神经网络架构。一年后,谷歌紧跟着推出了BERT模型。
透过BERT,刘知远已经意识到了Transformer给NLP技术路径带来的影响。“Transformer 现在有比较大的影响力,一个方面就是其每层都会利用 Attention(注意力)来捕捉全局的信息,能够提升长程依赖的学习能力,这是 CNN 所不具备的。同时Transformer能在GPU上得到非常好的加速,可以从更多训练数据学习更好的效果,这是RNN 系列模型难以做到的。”刘知远在一次访谈中表示。
2019年1月,刘知远便组织清华NLP实验室的同学在雁栖湖一家酒店开了7天会,最终决定放下手头其他工作,全力研究大模型。
2020年12月,刘知远带领团队推出了全球第一个中文预训练大模型CPM-1;2021年,刘知远便带着实验室的核心成员开始筹办新公司;2022年8月,面壁智能正式成立,距离ChatGPT的出现还有3个月。
2022年11月30日,ChatGPT发布后,新一轮人工智能浪潮如排山倒海般袭来。2023年2月,王慧文宣布入局,创办光年之外,开始四处广纳贤才。在收购一流科技Oneflow后,光年之外收购深言科技、面壁智能等“清华系”明星选手的消息也逐渐流传开来。
事实上, 面壁智能当时确实在寻找合作方。尽管面壁智能技术雄厚,团队也汇集了清华NLP实验室的大量人才,但办公司和做研究不同,只有技术还不够,组织管理、战略定位、商业模式如何打通等问题同样关乎企业的生死存亡。面壁智能的团队中基本都是工程师,很难解决这些繁杂的非技术难题。
很快,一则公告击穿所有传言。2023年2月,知乎宣布投资面壁智能;6月2日,知乎宣布公司合伙人、CTO李大海自即日起出任知乎的被投资企业面壁智能的董事和CEO,负责面壁智能战略发展和日常运营管理。
李大海,北京大学数学系硕士毕业,毕业后加入 Google 成为Google 中国创始员工之一,后在云云网任工程总监,在豌豆荚任搜索技术负责人,连续 12 年创业经验。2015年加入知乎,任知乎合伙人、CTO;负责知乎整体技术体系搭建,分管社区治理和用户体验中心,具备顶级技术体系搭建、战略规划、技术管理和商业化落地经验,从零开始为知乎搭建搜索和推荐业务,知乎 AI“智能社区”发起人,帮助知乎实现从百万到亿级MAU的跨越、并形成相对稳定的商业模式和多元化收入来源。
知乎和面壁智能,是一对互利互惠的组合。
李大海曾在一次访谈中谈起对面壁智能的投资,他说:“这是我作为(知乎)CTO发起的唯一一个项目。”当时,作为中等梯队的互联网企业,又是上市公司,面对全新的技术浪潮,知乎想要热情拥抱,又无法向创业公司一样义无反顾地投入其中。面壁智能则为知乎补上技术力量。
对面壁智能而言,知乎手中有中文互联网世界大量优质语料,是大模型训练的必不可少的养料。
在李大海的带领下, 面壁智能也在稳步前进。2023年4月,知乎与面壁智能宣布联合研发的首个中文大模型“知海图AI”和应用“热榜摘要”正式面世;5月27日,李大海在2023数博会上披露了双方合作的最新进展,包括宣布面壁智能研发的中文基座大模型CPM-Bee10b全面开源,发布对话类模型产品“面壁露卡”,以及内测第二款知乎场景下的模型应用“搜索聚合”。在锚定Agent方向的同时,基座模型也在不断追赶世界领先水平。2023年11月,面壁智能发布了最新的千亿多模态大模型CPM-Cricket,可以对标GPT-3.5的水平。
值得注意的事,面壁智能是在大量开源成果的基础上进一步探索的。早在面壁智能成立前,2022年4月,刘知远就带领团队发起了OpenBMB的开源社区,做了很多大模型的开源技术和工具。
过去一年,面壁智能的科研团队从十几人迅速扩张到100多人,平均年龄不过28岁。公司CTO曾国洋年仅25岁,一直跟随刘知远带领团队开发CPM系列大模型。
面壁智能最终能走多远,还是需要看能否形成一套闭环的商业模式。
在商业路径的选择上,李大海曾表示:“面壁智能更侧重C端。一方面,在公司的组织能力上,目前面壁智能的基因更偏向to C,所以在to B业务上,我们倾向于选择擅长跟客户沟通、交付能力强的合作伙伴,我们去提供平台、工具,合作伙伴去做好交付落地工作。”
值得注意的是,此次“小钢炮”发布会接近尾声时,李大海放出了一个“彩蛋”,即面壁智能推出的C端应用“心间”。
可以看到,从大模型到Agent再到C端应用,面壁智能的技术路线正在越来越清晰。
(封面图来源:面壁智能)

 2024-02-01
2024-02-01

 3687
3687 0
0 0
0 0
0
