
OpenAI给Figure带来了什么?
作者|王博 艾伦
2021年夏天,OpenAI悄然解散了它的机器人团队,理由是缺乏训练机器人使用人工智能进行移动和推理所需的数据,研发受到了阻碍。
当时,在美国创业孵化器Y Combinator的论坛上,BuzzFeed数据科学家马克思·伍尔夫(Max Woolf)直言 :“一种可能准确但带有讽刺意味的观点是,研究语言模型比研究机器人学具有更高的投资回报率和更低的风险。”
事实证明,OpenAI的确在大语言模型方面取得了更大突破。
不过,OpenAI忘记机器人了吗?
「甲子光年」在2023北京智源大会上注意到,OpenAI CEO萨姆·奥尔特曼(Sam Altman)谈到了曾经的机器人研究,他说:“我们对此很感兴趣,也有过挣扎,希望有朝一日,我们能重拾机器人的研究。”
现在,他们又入局了。OpenAI与人形机器人初创公司Figure合作推出的Figure 01机器人,凭借一段2分35秒的视频刷爆全网,视频中的Figure 01展现出了惊人的理解、判断、行动和自我评价的能力。
这就是OpenAI和Figure宣布合作13天后的成果。此前,Figure已从亚马逊创始人贝索斯(Bezos)、英伟达、OpenAI和微软等巨头那里筹集了约6.75亿美元的资金,公司估值达到了26亿美元。
除了资金,OpenAI还给Figure带来了什么?
1. Figure 01做到的和没做到的
Figure高级AI工程师科里·林奇(Corey Lynch)介绍,在和OpenAI合作后,Figure 01机器人可以做到:
描述其周围环境;
在做决策时使用常识推理。例如,“桌子上的餐具,比如盘子和杯子,很可能会放入沥水篮里”;
将模糊的、高层次的请求转换成一些情境适当的行为。例如,将“我能吃点儿什么”翻译成“给那个人一个苹果”;
用简单的英语描述它为什么执行了特定的行动。例如,“这是我能从桌子上给你提供的唯一可食用的物品”。

Figure 01演示做家务,图片来源:Figure
国内某头部机器人公司算法专家梁亮告诉「甲子光年」,接入GPT4V后,Figure 01机器人对环境的感知有了“巨大提升”,对人类指令的理解以及任务完成度“非常高”,并且在执行完成后的自我评估“很到位”。
北京大学计算机学院助理教授、博士生导师董豪表示,OpenAI和Figure合作,带来了机器人上层的感知决策。
“它其实是分两层,一层是感知决策,通过大模型来实现。因为大模型本来就具备感知能力,感知模型将逐步被大模型取代。然后它要输出Set-point(设定点),其实就是我们说的以物体为中心(Object-centric)的表达。”董豪告诉「甲子光年」,“还有一层是机器人操控,通过小模型实现,可达到高频200hz。然后通过运控算法,做全身控制,让手去到指定的位置。”
Figure团队介绍,Figure 01机器人由OpenAI提供视觉推理和语言理解能力,由Figure的神经网络提供快速、低层、灵巧的机器人动作能力。
为了实现视频中的效果,Figure研究人员将机器人摄像头捕获的图像和机载麦克风捕捉到的语音转录文本,输入到一个由OpenAI训练的大型多模态模型中,然后由该模型处理对话的整个历史记录,得出语言响应,然后通过文本到语音的方式将其回复给人类。
“同样的模型,也负责决定在机器人上运行哪些学习的闭环行为来完成给定的命令,将特定的神经网络权重加载到GPU上并执行策略。”林奇在X上分享道。
利用一个神经网络便完成了从语音输入到感知、推理、决策以及行为指令输出全过程,这被Figure称为“端到端神经网络”(end-to-end neural networks)。
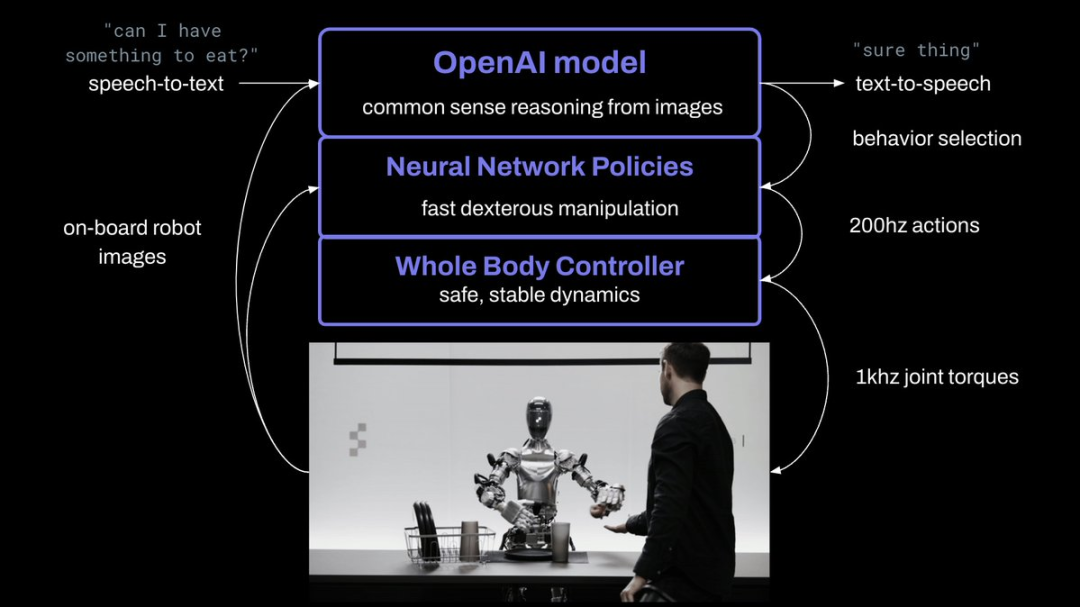
Figure 01原理解释,图片来源:Figure
但是“端到端”的说法,引发了一些讨论。
出门问问创始人、CEO李志飞认为,原理上,Figure看起来类似于Google在2023年3月发布的PaLM-E和RT-1的pipeline组合,而不是Google于2023年7月发布的端到端模型RT-2。
“'端到端'这个事,不同人的理解不一样。”董豪解释,“有的人认为RT-2这种直接输出action的才叫'端到端',但是那种方法缺点很明显,调用大模型的频率比较高,算力消耗特别大,而且很难做到比较高的决策速度。Figure说的‘端到端’,不是指直接输出action,而是由高频的模型来输出action。”
还有一个争议,Figure 01的演示视频是不是“摆拍”?
尽管Figure创始人布雷特·阿德科克(Brett Adcock)表示,机器人没有远程操作,而且这个视频是以1.0倍速(正常速度)连续拍摄的,但是质疑者认为,视频中并不是一个陌生的环境,而是精心设计过的,且拍摄过程中失败的次数难以估计,最终Figure选取了表现最好的一次。
人工智能和机器人领域技术专家、机器姬创始人刘智勇分析:“我认为没有摆拍,只是它的泛化能力,尤其是在陌生环境泛化、具身控制泛化方面,没有通过视频表现出来。如果把这个机器人丢到一个全新的环境当中去,它可能就不行了,但是在这个环境、这个时刻,它是完全自主运行的。”
阿德科克近期受访时也坦言,在开放环境中完成交互是Figure正在重点努力的方向。
刘智勇告诉「甲子光年」,当天晚上看到视频的第一反应“没有那么震撼”,因为视频里展现的机器人技术都是业内熟知的,“比如推理能力、视觉描述能力和任务规划能力,之前学术界的论文和demo里都有过展示。”
在他看来,这次OpenAI和Figure展现出来的“真正的新东西”是基于Transformer架构的控制网络以及Transformer网络背后的数据收集(data collection)系统。
在机器人领域,数据收集系统是指一套用于从机器人及其所处环境中获取信息的工具和方法。这样的系统对于机器人的学习和进步至关重要,因为它为机器学习算法提供了必要的输入,使机器人能够通过经验改善其性能。
“通过一套硬件设备,提供标准化的通用的训练数据。因为数据收集系统的存在,才可以做Transformer的训练。我觉得这是一个巨大的突破,而不在于机器人本体突破。”刘智勇说。
而此前OpenAI解散机器人团队的理由就是缺乏训练机器人使用人工智能进行移动和推理所需的数据,由此推断,OpenAI能和Figure合作,也与其数据收集系统相关。
OpenAI此次用在Figure 01机器人上多模态模型也引发了很多人关于Sora用于机器人领域的猜测。李志飞并不认同两者之间的关联,“Figure与Sora一点关系都没有,因为Sora现阶段主要是生成,不是理解,就算未来Sora既能理解也能生成,是否能端到端做到200hz的决策速度也是一个很大的问题。”
还有人会担心大模型的上下文长度限制以及“幻觉”问题,会对机器人行为产生影响。对此,刘智勇认为:“通过TokenLearner(一种视觉表征学习方法)来优化输入数据,可以解除上下文窗口限制。而幻觉问题可以用self reflection机制或者叫内心独白机制来解决,通常是通过一个hierarchical planning(层次化规划)的机制来去解决任务规划的问题,机器人的幻觉可能不只是语言层面,还需要通过环境可供性和行为似然性解决视觉、语言和行动三者的grounding的问题。”
2.差距有多大?在哪里?
Figure 01机器人演示视频破圈后,「甲子光年」与多位国内人工智能与机器人领域的学者、从业者进行了交流,业内人士普遍认为“效果不错”但“并不震撼”,很多技术此前“已有研究成果”,且国内的相关研究也“走在前列”。
但是,为什么Figure 01机器人没有诞生在国内?
梁亮告诉「甲子光年」,目前国内大部分厂商和Figure的方案类似,都是通过大模型进行感知、推理、决策,通过小模型抓取数据以及视觉判断,但是Figure 01机器人能如此优秀地与物理世界交互,离不开OpenAI大模型的加持,“差距不是十天半个月的,至少是一年多。”
刘智勇也认为,国内与世界最先进的具身智能的差距在“一年到一年半”。但他的观点有所不同,在他看来,主要是“数据收集硬件方面的差距”。
“我觉得大模型能力并不会限制具身智能发展,因为行为选择中间层的使用说明已经不是一个‘端到端’的方案了,而是感知决策和控制分块的。视觉语言模型的感知和大语言模型的决策并不存在真正的瓶颈,国内外差别不一定很大。”刘智勇对「甲子光年」说,“真正的聚焦点还是具身控制,我们是否能够搭建起一套完整数据收集系统,能否形成一个数据的飞轮和scaling law(规模法则)的出现,另外数据收集系统还要有标准的数据格式。”
刘智勇介绍,国内目前缺少一套公认的数据收集系统以及模型训练的流程、数据递归生成的pipeline。“换句话说,我们还无法通过一套数据收集硬件设备,提供标准化的通用的训练数据。Figure 01正是因为这个系统的存在,可以做Transformer的训练。”
在ARK invest的一次访谈中,阿德科克就曾提到,收集数据并用这些数据来训练AI系统是Figure最重要的事情之一,“我们需要思考如何收集数据,如何在规模上考虑这个问题,以及如何成功地、递归地通过AI数据引擎循环运行。我们花了很多时间来思考如何在规模上做到这一点,以及如何在早期运营中开始这样做。”
换言之,规模化收集数据是Figure保持长期竞争力的关键。只有批量化产出机器人,并在全球范围内推广,才能真正完成人形机器人的内循环,搭建起人形机器人的数据飞轮。
此外,训练数据所需的算力资源也是不容忽视的影响因素。
不过,近期国内的机器人研究也有新进展,且关注点就在Figure 01本次没有展现的泛化能力。北大董豪团队发布的最新具身大模型研究成果——ManipLLM的论文已被计算机视觉领域顶会CVPR 2024接收。
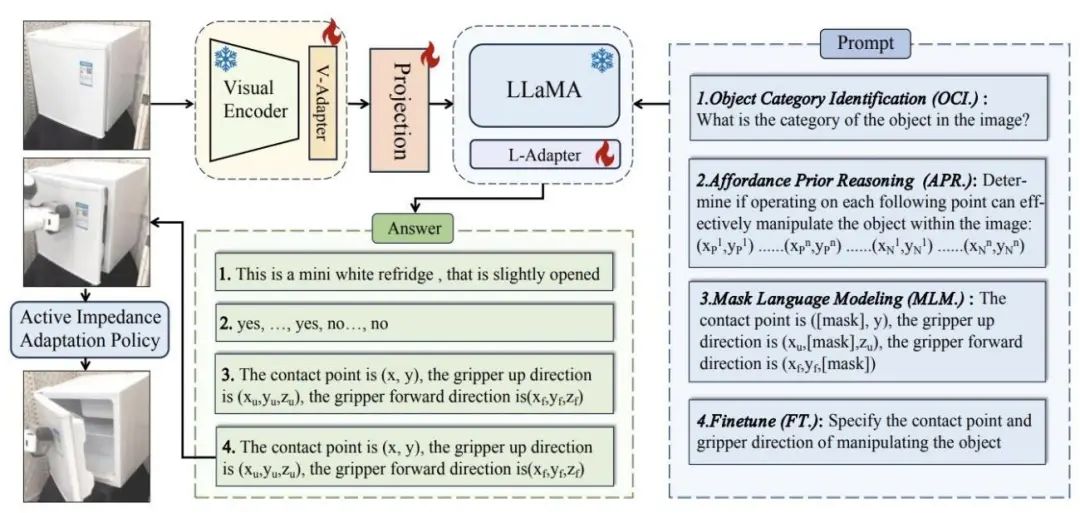
ManipLLM训练策略示意图,图片来源:受访者
“我们的大模型重点是为了解决可泛化的物体操作。”董豪告诉「甲子光年」,“我们提出了使用大模型直接在物体上输出动作的方法,而不是输出机器人本体的动作,这样可以提高机器人的泛化能力。”
在仿真和真实世界中,ManipLLM在各种类别的物体上均取得了令人满意的效果,证明了其在多样化类别物体中的可靠性和适用性。
今年3月初,刘智勇创办的机器姬公司推出了面向科研和教育市场可销售的家用机器人本体。机器姬不仅成功推出了具有长周期任务规划能力和基础操作能力的文生行动推理智能体。同时,他们还针对科研和教育市场推出了家用机器人本体科研平台,旨在为高校和研究机构提供一个开放的研发平台,以促进具身智能领域的科学研究和教学。
2023年底,工信部印发《人形机器人创新发展指导意见》,首次以单独文件形式对人形机器人发展做出全面清晰的战略规划部署。意见指出,人形机器人集成人工智能、高端制造、新材料等先进技术,有望成为继计算机、智能手机、新能源汽车后的颠覆性产品,将深刻变革人类生产生活方式,重塑全球产业发展格局。
同样是在2023年底,“人形机器人第一股”优必选在港交所挂牌上市也给国内机器人行业注入一针“强心剂”。人形机器人有没有可能像中国新能源产业一样引领全球?优必选创始人、董事长兼CEO周剑对此很有信心:“可以非常确定的是,人形机器人的未来要看中国。”
3.OpenAI的机器人梦想
OpenAI最初就有研究机器人的计划,早期OpenAI的主要目标就包括了制造“通用”机器人和使用自然语言的聊天机器人。
“OpenAI的许多早期探索都与电子游戏、多代理模拟和机器人有关,他们在这些领域广泛探索并取得了巨大成功。”OpenAI前科学家乔尔·雷曼(Joel Lehman)告诉「甲子光年」。
2018年7月30日,OpenAI发布研究文章《学习灵巧性(Learning dexterity)》,并宣称:“我们训练了一只类人机器人手,能够以前所未有的灵巧程度操纵物理物体。”

Dactyl,图片来源:OpenAI
这个系统名为Dactyl,Dactyl从零开始学习,使用与OpenAI Five相同的通用强化学习算法和代码。OpenAI的研究结果表明,有可能在模拟环境中训练智能体,并让它们解决现实世界的任务,而无需对世界的物理精确建模。
尽管世界上第一只人形手在几十年前就开发出来了,但使用它们有效地操纵物体一直是机器人控制领域面临的挑战。使用传统机器人方法进行灵巧操纵的进展缓慢,并且当时的技术在操纵现实世界中的物体时,能力仍然有限。
Dactyl亮相前一个月,OpenAI发布了GPT-1,正式踏上GPT大模型之旅。此时的 OpenAI的类人机器人,还未与GPT大模型产生关联。
2019年,OpenAI机器人团队表示,Dactyl已经学会了单手解决魔方问题,用3分多钟独自摸索复原了魔方。OpenAI将这一壮举视为机器人附属物的灵巧性和它自己的AI软件的飞跃。
“很多机器人都能很快解决魔方问题,这些机器人都是被制造出来专门解魔方的。”OpenAI机器人技术负责人彼得·韦林德(Peter Welinder)说,“OpenAI的机器人团队有着截然不同的雄心壮志,我们正在试着制造一个通用机器人,就像我们的手可以做很多事情,而不仅仅是完成一项特定的任务。”
Dactyl就是一种“自学习”的机械手,可以像人类一样完成新的任务。OpenAI希望有一天,Dactyl将有助于人类开发出科幻小说中的那种类人机器人。
这一年,OpenAI推出了GPT-2,发现了通往新大陆的航海图。
随后的2020年,OpenAI将所有精力和资源押注在GPT大模型上,并发布了GPT-3。这在当时是一个外界无法理解非主流技术路线,持续下注的行为一度被视作信仰。OpenAI实验室逐渐剔除了所有实验中的项目,力出一孔。
2021年夏天,OpenAI的机器人团队等来了解散的消息。
不过,OpenAI没有放弃打造机器人的梦想。
2022年底,ChatGPT的巨大成功让OpenAI获得了大量资源,不过这一次,OpenAI不再执着于完全自研,而是投资技术路线“对口”的初创公司。2023年3月,OpenAI投资了来自挪威的人形机器人公司1X Technologies。
然后就是今年2月29日,OpenAI对Figure的投资与合作。

OpenAI与Figure合作,图片来源:Figure
有趣的是,1X与Figure的选择的技术路线都是端到端的神经网络对于机器人的控制。
不负众望,Figure在与OpenAI宣布合作后13天,便发布了Figure 01的全新演示视频,惊艳世界,这再次证明了OpenAI对于技术路线的超强洞察力。
尽管OpenAI与Figure的合作顺畅,但OpenAI并未把宝都压在一家机器人公司上。
当地时间3月12日,一家名为Physical Intelligence的公司宣布在旧金山成立,目标是“为机器人构建大脑”。根据其官网介绍,Physical Intelligence是一家将通用目的人工智能带入物理世界的新公司,团队由工程师、科学家、机器人专家和创业者组成,致力于开发基础模型和学习算法,为当今的机器人和未来的物理驱动设备提供动力。
公司在其“简陋”的官网上写道,“我们感谢Khosla Ventures、Lux Capital、OpenAI、Sequoia Capital和Thrive Capital的支持和合作。”
不断下注人形机器人公司,OpenAI重燃了机器人梦想。
在OpenAI创立之初,埃隆·马斯克(Elon Musk)、萨姆·奥尔特曼(Sam Altman)、格雷格·布罗克曼(Greg Brockman)、伊利亚·苏茨克维(Ilya Sutskever)等人曾联合发文称:“我们正致力于利用物理机器人(现有而非OpenAI开发)完成基本家务。”
而这次Figure 01机器人演示的正是完成基本家务。
曾经拥有共同梦想的人,已经分道扬镳、对簿公堂,但对于马斯克来说,他在机器人领域又一次迎来了自己的“老朋友”也是“死对头”——奥尔特曼。
*参考资料:
《OpenAI和Figure机器人背后的技术原理是什么?》,飞哥说AI
《The Future of Human-like Robots with Figure AI’s Brett Adcock》,ARK invest
《Learning dexterity》,OpenAI
(封面图来源:Figure)

 2024-03-17
2024-03-17

 3678
3678 0
0 0
0 0
0
