大模型,需要AI基础设施的全面升级。
作者|赵健
再过一个月,ChatGPT发布就满一周年了。
这一年中,科技行业毫不吝啬地把ChatGPT比作“互联网的诞生”“新一轮工业革命”“AI的iPhone时刻”。这些称谓有一个共同的特点,都是把ChatGPT以及底层的大模型技术比作了工业革命之后水电煤一样的基础设施。
因为是基础设施,所以我们看到了云服务商巨头微软、谷歌、亚马逊,芯片巨头英伟达、英特尔,以及软件巨头Salesforce等领先的科技公司,纷纷重金投入大模型领域。在大的经济周期下行的背景下,生成式AI赛道却在逆势融资,百模大战愈演愈烈。
大模型的发展需要更强壮的AI基础设施,对构成基础设施的芯片与云而言,既有机会又是挑战。
大模型对以GPU为代表的芯片的影响,已经从英伟达今年狂飙的股价与利润来体现;大模型对云的影响,之前并不明显,但多家云服务商预计影响将逐渐从2023年第四季度起体现。亚马逊CEO安迪·贾西在上周称,预计生成式AI所带来的机遇将在未来几年为亚马逊AWS云服务带来“数百亿美元”的收入。
在国内,大模型也成为云服务商未来十年甚至二十年的核心战略。在昨天开幕的2023年阿里云栖大会上,亚太地区排名第一的阿里云宣布了面向大模型时代的重大升级——阿里云将通过从底层算力(IaaS)到AI平台(PaaS)再到模型服务(MaaS)的全栈技术创新,升级云计算体系,要打造一朵AI时代最开放的云。
具体而言,阿里云人工智能平台PAI全面升级,发布自研大模型通义千问2.0并宣布即将开源720亿参数版本,同时新推出一站式模型应用开发平台阿里云百炼。阿里云魔搭社区的模型下载量也已突破1亿,免费为开发者提供超3000万小时的GPU算力。
“计算,为了无法计算的价值”,这是今年云栖大会的主题,也是八年前第一届云栖大会的主题。2015年阿里云凭借完全自研的云计算操作系统横空出世,今天,阿里云又站在了AI技术驱动云计算变革时代的新起点。
这一次,阿里云能够继续保持领先吗?

1.为什么说做大模型上云已成必然?
要想理解阿里云的大模型思路,需要先从大模型与云计算的关系来看。
整个2023年,以GPU为代表的算力无疑是大模型讨论最多的话题之一,而云的重要性似乎被忽视了。但实际上,同为基础设施的云服务,也是驱动大模型发展的核心力量,甚至是“最佳拍档”。
大模型对于云服务商而言意味着新的增长力。在2023年前两个季度,市场的反馈并不明显。但今天,变化已经发生。
微软、谷歌、亚马逊已经在上周发布最新季度的财报。在生成式AI的驱动下,以Azure为核心的微软智能云并未如市场所预期的增长放缓,反而增速超过30%;AWS的收入结束了此前连续六个季度的放缓,并预计生成式AI会在未来今年带来数百亿美元的收入。市场占有率排在微软与AWS之后的谷歌,由于云收入低于预期,股价一度大跌9%。
大模型究竟为什么需要云?因为仅仅有GPU是远远不够的,它需要“数据中心级”的重构。
2009年,阿里云就提出“数据中心是一台计算机”的理念,如今,AI时代更加需要这样的技术体系。阿里云CTO周靖人认为,本次AI技术变革的本质,背后是整个计算机体系的全面升级。
在人工智能的小模型时代,依靠的是传统数据中心服务器中的CPU,向外输出“通用计算”能力——处理操作系统、系统软件与应用程序这一类拥有复杂指令调度、循环、分支、逻辑判断与执行等程序任务。但到了大模型时代,训练大模型需要超大规模的数据处理和并行计算能力,算力从CPU转向了GPU,形成了以GPU为核心的新体系,英伟达CEO黄仁勋称之为“加速计算”。
加速计算是一个全栈挑战,它必须把所有的软件、所有的框架库、所有的算法集成在一起进行工程化,这些工作不仅仅是针对一颗芯片,而是针对整个数据中心。要获得最佳性能,需要对网络操作系统、分布式计算引擎、网络设备、交换机、计算架构等全栈内容进行优化。
因此,黄仁勋今年曾信誓旦旦地说:“我们正处于一个为期十年的数据中心智能化的第一年。”
周靖人也表示:“此前大众可能有一个误解,即只要有足够的GPU,就可以连接在一起获得更高的算力来支撑大模型的发展。但今天大模型并非依靠一个计算单元,而是需要成千上万个计算单元联合起来,这是一个非常复杂的分布式系统。”
以微软为例,为了支持OpenAI训练ChatGPT,专门设计了一台10000张A100芯片连接起来的超级计算机,在获得高效能算力的同时,也要解决数据中心的散热、断电等工程问题的优化。
可以说,没有微软的云服务支持,就不会有今天的ChatGPT。大模型训练,云不可或缺。
在云栖大会上,阿里云也针对大模型升级了AI基础设施,提供更高性能、更低成本的智能算力。周靖人介绍称,全新升级的阿里云人工智能平台PAI,底层采用HPN 7.0新一代AI集群网络架构,高效协同调度各类芯片,可支持高达10万卡量级的集群可扩展规模,让超大集群像一台计算机般高效运转。

据了解,阿里云PAI可支撑多个万亿参数大模型同时训练,超大规模分布式训练加速比高达96%,远超业界水平;在大模型训练任务中,更可节省超过50%算力资源,性能全球领先。
阿里云通义大模型系列就是基于人工智能平台PAI训练而成,包括最新升级的千亿级参数通义千问2.0。此外,在国内主流大模型中,超过一半在阿里云上训练而成,包括百川智能、智谱AI、零一万物、昆仑万维、vivo、复旦大学等头部企业及机构。
百川智能创始人兼CEO王小川表示:“百川成立仅半年便发布了7款大模型,快速迭代背后离不开云计算的支持。”百川智能和阿里云进行了深入合作,在双方的共同努力下,百川很好地完成了千卡大模型训练任务,有效降低了模型推理成本,提升了模型部署效率。
零一万物是一家致力打造 AI 2.0 时代的平台及应用的全球化公司,由李开复博士带队创办,即将于近日在Modelscope等平台正式推出自研大模型。零一万物联合创始人马杰表示:“阿里云PAI灵骏智算服务为零一万物提供了高性能AI训练集群和工程平台,助力零一万物自研大模型,推动其AI-first的技术和应用生态。”
半壁AI算力囊收阿里云,超过一半的中国头部大模型公司,用脚投票,全面拥抱云计算。做大模型就上云,已是必然。
2.大模型的落地解法
从做大模型,到用大模型,中间要经历漫长的落地过程。
基础大模型具备了通用的世界知识,但在具体的垂直业务场景中,比如金融、医疗、交通等领域,由于缺乏专业的“培训”,基础大模型并不能胜任这些场景的任务。
某头部国产大模型厂商发言人曾对「甲子光年」表示,大模型的落地痛点,在于行业客户常常带有“产品采购”思维,但现阶段的基础大模型,又不是一个可以开箱即用的产品,供给双方之间认知并未对齐。常用的解决方案,就是在基础大模型的基础上加入专业性的数据语料做二次训练或微调,得到一个专用的行业大模型。
谁来做行业大模型?有的是模型厂商自己做,有的是通过独立软件开发商(ISV)等第三方合作伙伴。对于这类新的AI交付方式业内并无更多经验可循。
为了降低大模型的开发门槛,推动大模型在千行百业的落地,阿里云在本次云栖大会上“打样”8个垂直行业模型——工作学习AI助手「通义听悟」、助力企业服务向智能化与多模态转型的「通义晓蜜」、AI阅读助手「通义智文」、个性化角色创作平台「通义星尘」、智能编码助手「通义灵码」、AI法律顾问「通义法睿」、专业健康助手「通义仁心」、智能投研助手「通义点金」,让大模型在金融、医疗、法律、编程、个性化创作等行业和场景中更易被集成。
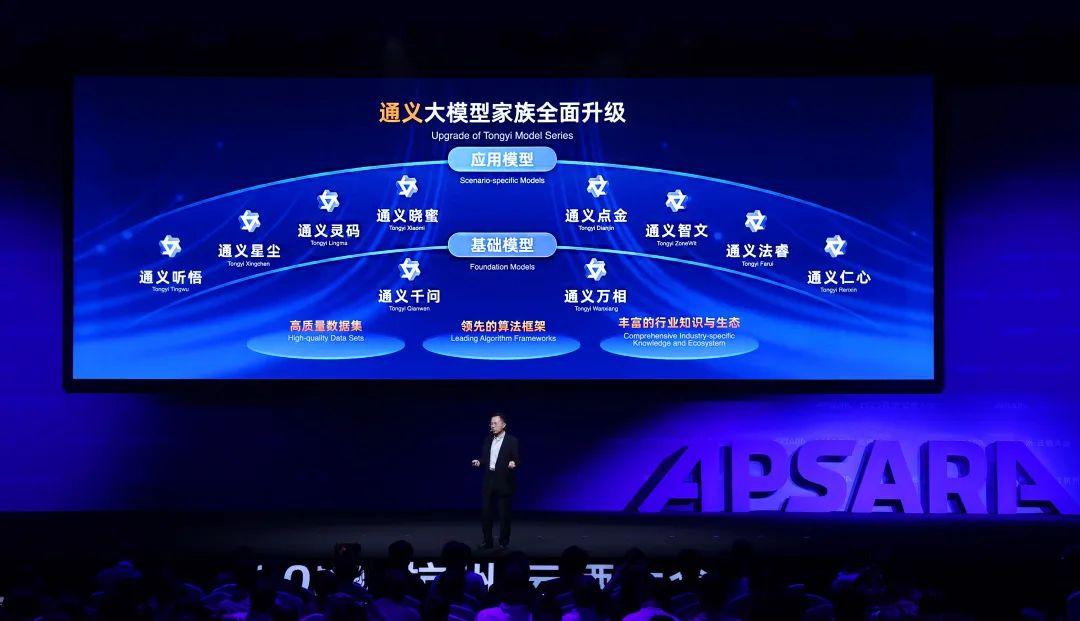
这8大垂直领域模型将通过网页嵌入、API与SDK调用等方式集成进各行各业,还将通过一站式大模型应用开发平台——阿里云百炼对外开放。
周靖人介绍,阿里云百炼集成了国内外主流优质大模型,提供模型选型、微调训练、安全套件、模型部署等服务和全链路的应用开发工具,为用户简化了底层算力部署、模型预训练、工具开发等复杂工作。开发者可在5分钟内开发一款大模型应用,几小时即可“炼”出一个企业专属模型,帮助企业和开发者把更多精力专注于应用创新。
“阿里云欢迎所有大模型接入阿里云百炼,共同向开发者提供AI服务。”周靖人表示。
目前,央视网、朗新科技、亚信科技等企业已率先在阿里云百炼上开发专属模型和应用,朗新科技云上训练出电力专属大模型,开发“电力账单解读智能助手”“电力行业政策解析/数据分析助手”,为客户接待提效50%、降低投诉70%。
阿里云百炼除了支持企业调出行业模型,还支持开发大模型应用。在未来,大模型应用的爆发,需要极大量的AI推理算力,需求增长了百倍、千倍。
黄仁勋也有类似的判断。最近NVIDIA官方发表了一篇与「黄氏定律(Huang's Law)」相关的技术文章,认为在未来单芯片性能和效率的AI推理性能,在不到十年的时间内将会提高1000倍以上。
英伟达投资的云计算创业公司CoreWeave联合创始人&首席战略官Brannin McBee此前在接受采访时曾举了一个更直观的例子:假如一家AI公司通过1万个GPU训练出大模型,那么在产品推向市场的1~2年内,他们大约会需要100万个GPU来支持整个推理需求。
如此巨大的AI推理需求,传统数据中心更无法满足,最佳伙伴依旧是云。今年,阿里云成功支撑火爆全网的妙鸭相机短时间高强度的流量爆发。阿里云已在全球30个地域建设了89个云计算数据中心,提供3000余个边缘计算节点,云计算的低延时、高弹性优点将发挥得淋漓尽致。
3. 开源模型与开放的云
对于今年刚刚起步的大模型而言,仍面临诸多不同选择,就像移动互联网时代有iOS与安卓两大操作系统阵营,大模型也正在经历闭源与开源的同步发展。
开源,能进一步激发技术创新,也能带动产业发展。不同于闭源的GPT-4那样不再公布更多技术细节,而是将其作为核心商业秘密来构建产品壁垒,开源模型与开源社区则直接将代码、模型、开发工具与数据集向开发者开放,比如Meta Llama2、Hugging Face等,这有效推动了大模型的学术研究与技术发展。
因此,开源大模型也吸引了众多科技公司布局,来对抗“闭源王者”GPT-4。比如,今年9月,全球最大的大模型开源社区Hugging Face得到了谷歌、亚马逊、英伟达、Salesforce、AMD、英特尔、IBM 和高通的共同投资,估值达到45亿美元。今天,Hugging Face上的预训练模型数量从此前积累的10万个增长到了超过30万个,数据集从1万个增长至5.8万个。
在国内,阿里云是头部大厂中最早做模型开源的公司,坚定选择开源开放,阿里云要打造一朵AI时代最开放的云。
从今年8月开始,阿里云陆续开源了通义千问7B、14B参数的通用模型与对话模型。在本次云栖大会上,周靖人再次宣布通义千问72B模型即将开源,将成为中国参数最大的开源模型。
值得一提的是,阿里云自研大模型与第三方模型并非竞争关系。恰恰相反,阿里云为所有大模型提供开放的社区,还提供免费的GPU算力帮助开发者去体验三方大模型,截至目前阿里云已免费提供超3000万小时的免费GPU算力。
在阿里云魔搭社区上,百川智能、智谱AI、上海人工智能实验室、IDEA研究院等业界顶级玩家,都在魔搭上开源首发他们的核心大模型。周靖人透露,魔搭社区现已聚集2300多款AI模型,吸引280万名AI开发者,AI模型下载量突破1亿,成为中国规模最大、开发者最活跃的AI社区。

“不同的场景会有不一样的需求,一个模型不可能服务所有需求,也不是只有一种对应方式。促进中国AI生态繁荣,才是阿里云的首要目标。”周靖人解释,阿里云不仅仅是服务某一类型客户,而是要通过训练及推理平台PAI、开放的模型社区魔搭、一站式模型服务平台“百炼”,来系统地服务和满足大模型生态中所有人的需求,共同促进生态繁荣。
至此,阿里云在大模型时代的“阳谋”已经清晰——通过打造AI时代最开放的大模型体系,满足并推进整个行业对算力和模型落地的需求升级,反过来再推动云计算的技术迭代升级,从而实现整个产业的良性循环发展。
可以预见,一场为期十年的AI驱动的云计算新周期开始了。
(封面图及文中配图来源:阿里云)

 2023-11-01
2023-11-01

 3231
3231 0
0 0
0 0
0
